十亿字语言建模
在我们上一篇博文中,我们介绍了一种结合强化学习和循环神经网络的视觉注意循环模型。在这篇 Torch 博文中,我们使用噪声对比估计 (NCE) [2] 在 Google 十亿词 (GBW) 数据集 [7] 上训练一个多 GPU 循环神经网络语言模型 (RNNLM)。这里介绍的工作是 Element-Research 多月断断续续工作的成果。数据集的庞大规模促使我们贡献了一些新颖的开源 Torch 模块、标准,甚至多 GPU 张量。我们还提供了脚本,以便您能够训练和评估自己的语言模型。
如果您只对生成的样本、困惑度和学习曲线感兴趣,请跳到结果部分。
词语与字符语言模型
在最近几个月,您可能注意到人们对生成字符级 RNNLM 的兴趣越来越高,例如 char-rnn 和最近的 torch-rnn。这些模型非常有趣,因为它们可以用来生成以下类似的字符序列
<post>
Diablo
<comment score=1>
I liked this game so much!! Hope telling that numbers' benefits and
features never found out at that level is a total breeze
because it's not even a developer/voice opening and rusher runs
the game against so many people having noticeable purchases of selling
the developers built or trying to run the patch to Jagex.
</comment>
以上是在 reddit 评论的样本的基础上,一次生成一个字符而生成的。如您所见,生成的文本的总体结构很好,至少乍一看是如此。标签的打开和关闭都是恰当的。第一句话很好:I liked this game so much!!,并且它与帖子的 subreddit 相关:Diablo。但是,读完剩下的部分,我们就可以开始看到字符级语言模型的局限性了。单个单词的拼写看起来很好,但是下一句话的意思很难理解(而且也很长)。
在这篇博文中,我们将展示如何使用 Torch 训练一个大规模的词级语言模型来生成独立的句子。词级模型比字符级模型有一个重要的优势。以以下序列为例(来自罗伯特·A·海因莱因的引言)
Progress isn't made by early risers. It's made by lazy men trying to find easier ways to do something.
经过分词后,词级模型可能会将此序列视为包含 22 个标记。另一方面,字符级模型将此序列视为包含 102 个标记。这个更长的序列使字符模型的任务比词语模型更难,因为它必须考虑更多标记之间在更多时间步上的依赖关系。字符语言模型的另一个问题是,它们需要学习拼写,除了语法、语义等。无论如何,词语语言模型通常比字符模型的错误率更低。 [8]
字符模型相对于词语语言模型的主要优势是,它们的词汇量非常小。例如,GBW 数据集将包含大约 800 个字符,而词语约为 800,000 个(在剪枝低频标记后)。在实践中,这意味着字符模型所需的内存更少,推理速度也比词语模型快。另一个优势是,它们不需要分词作为预处理步骤。
循环神经网络语言模型
我们的任务是构建一个语言模型,该模型最大化给定句子中先前词语的历史记录的下一个词语的可能性。下图说明了简单循环神经网络 (Simple RNN) 语言模型的工作原理
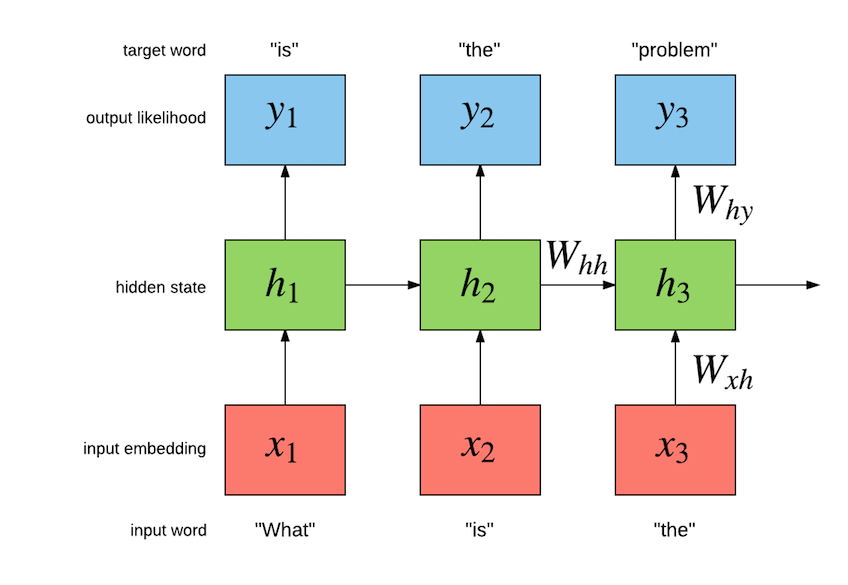
确切的实现如下
h[t] = σ(W[x->h]x[t] + W[h->h]h[t−1] + b[1->h]) (1)
y[t] = softmax(W[x->y]h[t] + b[1->y]) (2)
对于这个特定的例子,模型应该在给定“what”的情况下最大化“is”,然后在给定“is”的情况下最大化“the”,以此类推。Simple RNN 具有一个内部隐藏状态 h[t],它汇总了到目前为止输入的序列,因为它与最大化序列中剩余词语的可能性有关。在内部,Simple RNN 具有从输入到隐藏(词语嵌入)、从隐藏到隐藏(循环连接)以及从隐藏到输出(馈送到 softmax 的输出嵌入)的参数。从输入到隐藏的参数由一个 LookupTable 组成,它学习将每个词语表示为一个向量。这些向量形成词语的嵌入空间。输入 x[t] 到 LookupTable 是与词语 w[t] 相关的唯一整数。该词语的嵌入向量是通过索引嵌入空间 W[x->h] 获得的,我们用 W[x->h]x[t] 表示。从隐藏到隐藏的参数通过生成给定 h[t-1] 和 x[t] 的隐藏状态 h[t] 来模拟词语的时间依赖关系。这就是实际递归发生的地方,因为 h[t] 是 h[t-1](以及词语 x[t])的函数。从隐藏到输出层执行仿射变换(即 Linear 模块:W[x->y]h[t] + b[1->h]),然后是 softmax。这是为了估计给定先前词语的下一个词语上的概率分布 y[t],而先前词语由隐藏状态 h[t] 体现。标准是最大化给定先前词语的下一个词语 w[t+1] 的可能性:P(w[t+1]|w[1],w[2],...,w[t])。
使用 rnn 包很容易构建 Simple RNN(参见 简单 RNN 示例),但它们并不是唯一可以用来模拟语言的模型。还有更先进的长短期记忆 (LSTM) 模型 [3],[4],[5],它们具有特殊的门控单元,可以促进梯度通过更长序列的反向传播。
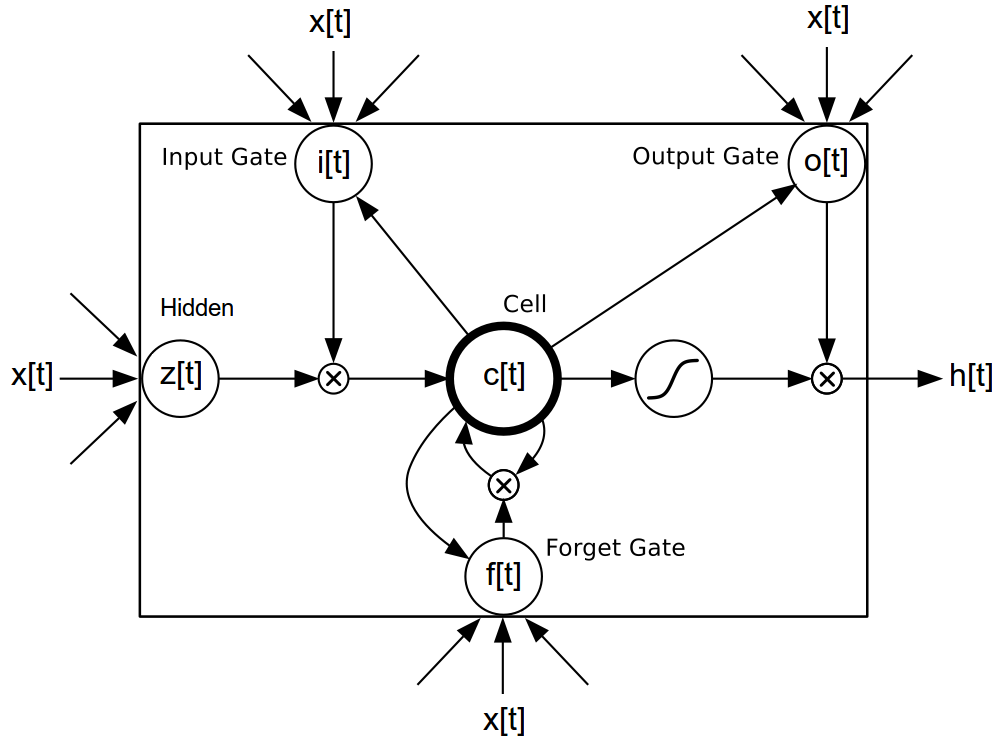
确切的实现如下
i[t] = σ(W[x->i]x[t] + W[h->i]h[t−1] + b[1->i]) (3)
f[t] = σ(W[x->f]x[t] + W[h->f]h[t−1] + b[1->f]) (4)
z[t] = tanh(W[x->c]x[t] + W[h->c]h[t−1] + b[1->c]) (5)
c[t] = f[t]c[t−1] + i[t]z[t] (6)
o[t] = σ(W[x->o]x[t] + W[h->o]h[t−1] + b[1->o]) (7)
h[t] = o[t]tanh(c[t]) (8)
主要优势是,LSTM 可以学习在更长时间步长之间分离的词语之间的依赖关系。它不像不同的门控单元那样容易出现梯度消失问题,因为不同的门控单元可以在反向传播期间保留梯度。为了创建 LM,词语嵌入(W[x->h]x[t] 在等式 1 中)将被馈送到 LSTM,生成的隐藏状态将被馈送到等式 2 中。
语言模型的误差传统上使用困惑度来衡量。困惑度是衡量模型在看到一段文本序列时有多惊讶的指标。如果您向它输入一个词语序列,并且对于每个后续词语,模型能够以高可能性预测下一个词语是什么,那么它将具有较低的困惑度。如果长度为 T 的序列 s 中的下一个词语由 s[t] 索引,并且模型推断的可能性为 y[t],使得该词语的可能性为 y[t][s[t]],那么该词语序列的困惑度为
log(y[1][s[1]) + log(y[2][s[2]) + ... + log(y[T][s[T])
PPL(s,y) = exp( -------------------------------------------------------- )
-T
困惑度越低越好。
加载 Google 十亿词数据集
对于我们的词级语言模型,我们使用 GBW 数据集。该数据集不同于 Penn Tree Bank,因为句子彼此独立。因此,我们的数据集包含一组独立的变长序列。可以使用 dataload 包轻松加载该数据集
local dl = require 'dataload'
local train, valid, test = dl.loadGBW(batchsize)
如果磁盘上没有找到数据,以上操作将自动下载数据,并返回训练集、验证集和测试集。这些是 dl.MultiSequence 实例,它们具有以下构造函数
dataloader = dl.MultiSequence(sequences, batchsize)
该 sequences 参数是 Lua 表或 tds.Vector,其中每个元素都是包含一个独立序列的张量。例如
sequences = {
torch.LongTensor{424,158,115,667,28,505,228},
torch.LongTensor{389,456,188},
torch.LongTensor{77,172,760,687,552,529}
}
batchsize = 2
dataloader = dl.MultiSequence(sequences, batchsize)
注意序列的长度如何变化。与所有 dl.DataLoader 子类一样,dl.MultiSequence 加载器提供了一种方法,可以从数据集中对一批 inputs 和 targets 进行子采样
local inputs, targets = dataloader:sub(1, 10)
该 sub 方法采用子序列的 start 和 end 索引进行索引。在内部,这些索引仅用于确定请求的多序列的长度(seqlen)。对 sub 的每次连续调用都将返回与之前连续的多序列。
返回的 inputs 和 targets 是 seqlen x batchsize [x inputsize] 张量,包含一批 2 个多序列,每个序列包含 8 个时间步长。从 inputs 开始
print(inputs)
0 0
424 77
158 172
115 760
667 687
28 552
505 0
0 424
[torch.DoubleTensor of size 8x2]
每一列都是包含多个序列(即多序列)的向量。独立的序列由零隔开。在下一节中,我们将看到 rnn 包如何使用这些零掩码时间步长在独立序列之间有效地忘记其隐藏状态(以列的粒度)。目前,请注意返回的 inputs 中如何包含原始 sequences,并且由零隔开。
该 targets 与 inputs 相似,但使用掩码 1 来分隔序列(因为 ClassNLLCriterion 否则会抱怨)。与语言模型中常见的情况一样,任务是预测下一个词语,使得 targets 相对于相应的 inputs 延迟一个时间步长
print(targets)
1 1
158 172
115 760
667 687
28 552
505 529
228 1
1 158
[torch.DoubleTensor of size 8x2]
通过调用 dl.loadGBW 返回的 train、valid 和 test 与上述内容具有相同的属性。只是数据集更大(它包含十亿个词语)。为了调试等,我们可以选择加载训练集的一个更小的子集。这将比默认训练集文件加载得快得多
local train, valid, test = dl.loadGBW({2,2,2}, 'train_tiny.th7')
以上操作将对所有集合使用 batchsize 为 2。使用 subiter 可以更容易地遍历 dataloader
local seqlen, epochsize = 3, 10
for i, inputs, targets in train:subiter(seqlen, epochsize) do
print("T = " .. i)
print(inputs)
end
这将输出
T = 3
0 0
793470 793470
211427 6697
[torch.DoubleTensor of size 3x2]
T = 6
477149 400396
720601 213235
660496 368322
[torch.DoubleTensor of size 3x2]
T = 9
676607 61007
161927 767587
248714 635004
[torch.DoubleTensor of size 3x2]
T = 10
280570 130510
[torch.DoubleTensor of size 1x2]
我们也可以将以上小批次作为一大块返回
train:reset() -- resets the internal sequence iterator
print(train:sub(1,10))
0 0
793470 793470
211427 6697
477149 400396
720601 213235
660496 368322
676607 61007
161927 767587
248714 635004
280570 130510
[torch.DoubleTensor of size 10x2]
注意,以上小批次如何与这大块对齐。这意味着数据按顺序进行迭代。
GBW 数据集中的每个句子都被封装在 <S> 和 </S> 标记中,分别表示序列的开始和结束。每个标记都映射到一个整数。因此,例如,您可以看到 <S> 在以上示例中映射到整数 793470。现在我们对数据集有信心了,让我们看看模型。
构建多层 LSTM
在本节中,我们将开始真正构建我们的多层 LSTM。我们将在到达输出层时介绍 NCE,从输入层开始。
该 lm 模型的输入层是查找表
lm = nn.Sequential()
-- input layer (i.e. word embedding space)
local lookup = nn.LookupTableMaskZero(#trainset.ivocab, opt.inputsize)
lm:add(lookup) -- input is seqlen x batchsize
我们使用 LookupTableMaskZero(LookupTable 的子类)来学习词语嵌入。主要区别在于它支持零索引,这些索引被转发为零张量。然后是实际的多层 LSTM 实现,它使用 SeqLSTM 模块
local inputsize = opt.inputsize
for i,hiddensize in ipairs(opt.hiddensize) do
local rnn = nn.SeqLSTM(inputsize, hiddensize)
rnn.maskzero = true
lm:add(rnn)
if opt.dropout > 0 then
lm:add(nn.Dropout(opt.dropout))
end
inputsize = hiddensize
end
如 rnn-benchmarks 代码库中所示,SeqLSTM 实现非常快。接下来,我们将 SeqLSTM 的输出(一个 seqlen x batchsize x outputsize 张量)拆分成一个表,每个时间步包含一个 batchsize x outputsize 张量。
lm:add(nn.SplitTable(1))
问题:输出层的瓶颈
Penn Tree Bank 数据集的词汇量只有 10000 个单词,相对容易用于构建词级语言模型。输出层在训练和推理中仍然是计算可行的,特别是对于 GPU 而言。对于这些较小的词汇量,输出层基本上是一个 Linear 层,后面跟着一个 SoftMax 层。
outputlayer = nn.Sequential()
:add(nn.Linear(hiddensize, vocabsize))
:add(nn.SoftMax())
然而,当使用大型词汇量训练时,例如构成 GBW 数据集的 793471 个单词,输出层很快就会成为瓶颈。例如,如果你使用 batchsize = 128(每批序列数)和 seqlen = 50(反向传播时间序列的大小)训练模型,该层的输出将具有 seqlen x batchsize x vocabsize 的形状,即 128 x 50 x 793471。对于 FloatTensor 或 CudaTensor 而言,这个单个张量将占用 20GB 的内存!对于 gradInput(即相对于输入的梯度)来说,这个数字可能会翻倍,而 Linear 和 SoftMax 都会为 output 存储一份副本,所以这个数字还会再次翻倍。
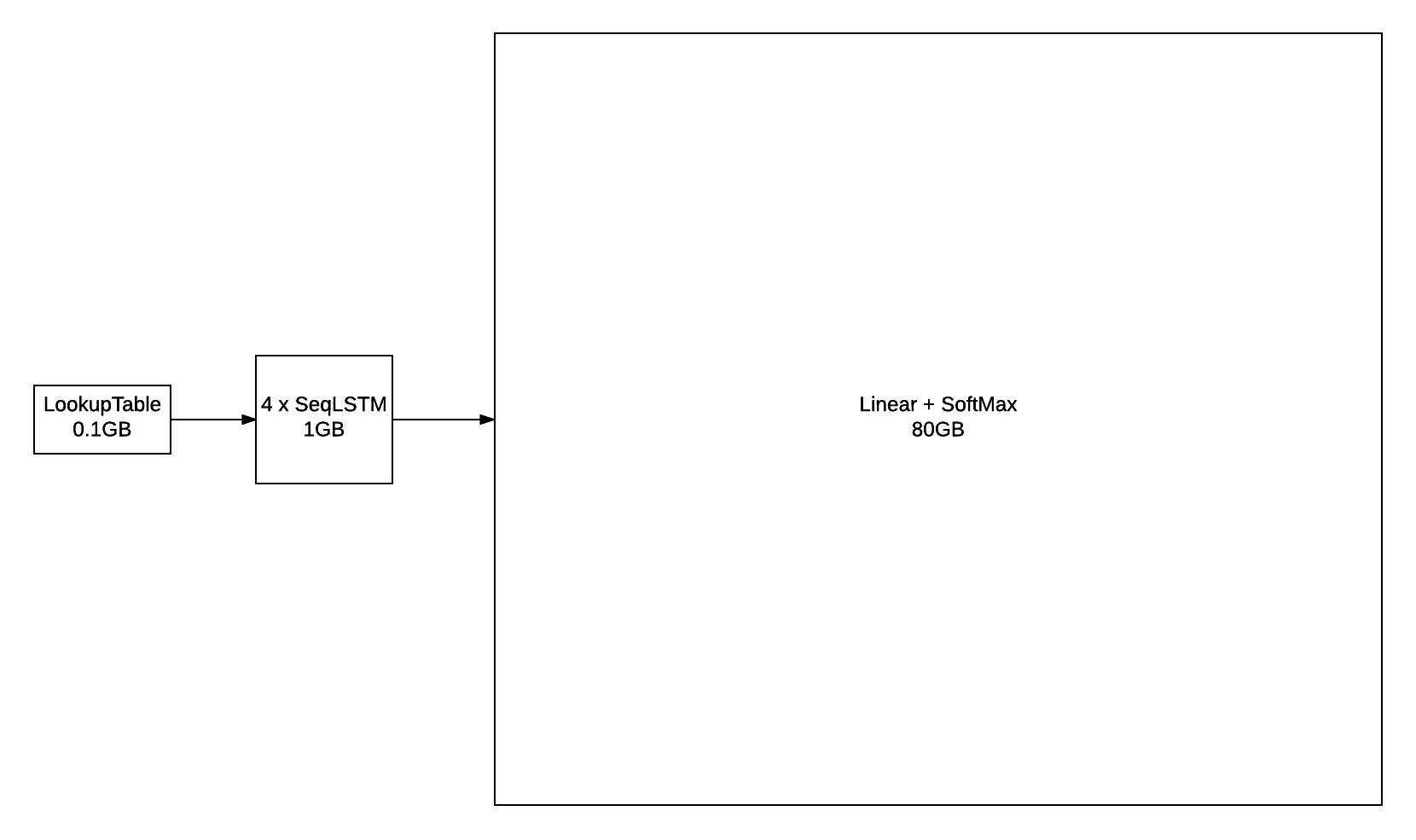
不包括参数及其梯度,上图概述了具有 2048 个单元的 4 层 LSTM 在 seqlen=50 下的近似内存消耗。即使你能找到某种方法将 80GB 放到 GPU 上(或者将其分配到多个 GPU 上),你仍然会遇到在合理的时间范围内向前/向后传播 outputlayer 的问题。
解决方案:噪声对比估计
LM 的输出层使用 NCE 来加速训练并减少内存消耗。
local unigram = trainset.wordfreq:float()
local ncemodule = nn.NCEModule(inputsize, #trainset.ivocab, opt.k, unigram, opt.Z)
-- NCE requires {input, target} as inputs
lm = nn.Sequential()
:add(nn.ParallelTable()
:add(lm):add(nn.Identity()))
:add(nn.ZipTable())
-- encapsulate stepmodule into a Sequencer
lm:add(nn.Sequencer(nn.MaskZero(ncemodule, 1)))
NCEModule 是一个更有效的版本。
nn.Sequential():add(nn.Linear(inputsize, #trainset.ivocab)):add(nn.LogSoftMax())
为了评估困惑度,模型仍然实现了 Linear + SoftMax。NCE 有助于减少训练期间的内存消耗(与上图进行比较)。
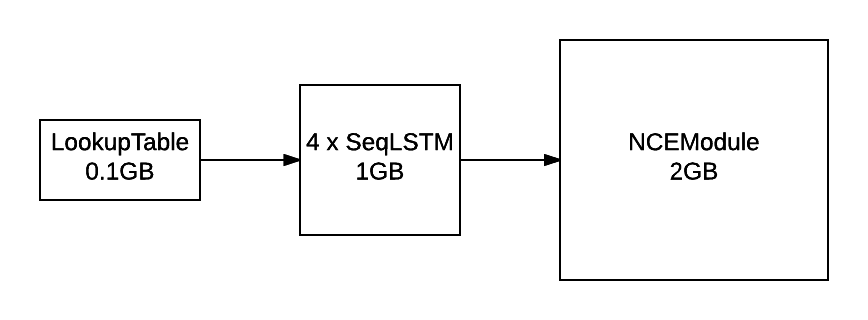
除了 NCECriterion 之外,NCEModule 还实现了在 [1] 中描述的算法。我不会详细介绍该算法,因为它涉及大量的数学运算,在参考文献中已经得到了更详细的描述。它的工作原理是,对于每个目标词(我们想要最大化其似然),从噪声分布(通常是单字分布)中采样 k 个词。
请记住,softmax 基本上是
exp(x[i])
y[i] = --------------------------------- (9)
exp(x[1])+exp(x[2])+...+exp(x[n])
其中 x[i] 是输出 Linear 层的第 i 个输出。上面的分母是瓶颈的原因,因为需要为每个输出 x[i] 计算 Linear。对于 n=797470 的词汇量来说,这代价过高。NCE 通过在训练期间用常数 Z 替换等式 9 的分母来解决这个问题。
exp(x[i])
y[i] = ------------ (10)
Z
这并不是训练期间真正发生的事情,因为通过上面的内容进行反向传播不会产生 x[j] 的梯度,其中 j~=i(j 不等于 i)。请注意,通过等式 9 进行反向传播会产生 Linear 的所有输出 x 的梯度(即对于所有 i)。等式 10 的另一个问题是,没有任何东西迫使 exp(x[1])+exp(x[2])+...+exp(x[n]) 近似于 Z。NCE 做的是将问题重新表述,以便可以将 k 个噪声样本包含在等式中,既可以确保一些(最多 k 个)负样本(即 x[j],其中 j)获得梯度,又可以确保等式 9 的分母近似于等式 10 的分母。k 个噪声样本是从噪声分布(即单字分布)中采样的。输出层 Linear 只需要为目标词和噪声采样词计算,这就是效率提升的地方。
上面的 unigram 变量是一个大小为 793470 的张量,其中每个元素都是语料库中对应单词的频率。使用类似 torch.multinomial 的方法从如此大的分布中进行采样可能会在训练期间成为瓶颈。因此,我们在 torch.AliasMultinomial 中实现了一个更有效的版本。后者多项式采样器比前者需要更多的设置时间,但这并不是问题,因为单字分布是恒定的。
NCE 使用噪声样本来近似归一化项 Z,其中输出分布为 exp(x[i])/Z,x[i] 是 Linear 对单词 i 的输出。对于 NCE 试图近似的 Softmax 来说,Z 是所有单词 i' 上 exp(x[i']) 的总和。对于 NCE 来说,Z 通常固定为 Z=1。我们的初步实验发现,将 Z 设置为 Z=N*mean(exp(x[i]))(其中 N 是单词数量,mean 是在一小批单词样本 i 上近似的)会得到更好的结果,但这是因为我们没有正确地初始化输出层参数。
NCE 论文(有很多)的一个显著特点是,它们经常忘记提到参数初始化的重要性。只有当 NCEModule.bias 初始化为 bias[i] = -log(N) 时,才能真正将 Z 设置为 Z=1。这是 [2] 的作者使用的方法,尽管论文中没有提到(我联系了其中一位作者以了解情况)。
对每个时间步和每个批次行采样 k 个噪声样本意味着 NCEModule 需要在内部使用类似 torch.baddbmm 的方法来计算 output。[2] 实现了一个更快的版本,其中噪声样本只抽取一次,并用于整个批次(但每个时间步仍然只抽取一次)。这使得代码更快,因为可以使用更有效的 torch.addmm 而不是 torch.baddbmm。[2] 中描述的这个更快的 NCE 版本是 NCEModule 的默认实现。可以通过 NCEModule.rownoise=true 来打开每个批次行的采样。
训练和评估脚本
这里介绍的实验使用了三个脚本:两个用于训练(你只需要使用一个)和一个用于评估。训练脚本的区别只在于使用的 GPU 数量。这两个脚本都在训练集上训练语言模型,并在验证集上进行提前停止。评估脚本用于衡量训练模型在测试集上的困惑度,或者生成句子。
单 GPU 训练脚本
我们通过 noise-contrastive-estimate.lua 脚本提供了一个用于单 GPU 的训练脚本。在 12GB NVIDIA Titan X 上运行以下脚本,在 321 个 epoch 后应该会得到 65.6 的测试集困惑度。
th examples/noise-contrastive-estimate.lua --cuda --device 2 --startlr 1 --saturate 300 --cutoff 10 --progress --uniform 0.1 --seqlen 50 --batchsize 128 --trainsize 400000 --validsize 40000 --hiddensize '{250,250}' --k 400 --minlr 0.001 --momentum 0.9
生成的模型将如下所示。
nn.Serial @ nn.Sequential {
[input -> (1) -> (2) -> (3) -> output]
(1): nn.ParallelTable {
input
|`-> (1): nn.Sequential {
| [input -> (1) -> (2) -> (3) -> (4) -> output]
| (1): nn.LookupTableMaskZero
| (2): nn.SeqLSTM
| (3): nn.SeqLSTM
| (4): nn.SplitTable
| }
|`-> (2): nn.Identity
... -> output
}
(2): nn.ZipTable
(3): nn.Sequencer @ nn.Recursor @ nn.MaskZero @ nn.NCEModule(250 -> 793471)
}
要使用大约三分之一的内存,可以将动量设置为 0。
评估脚本
评估脚本可以用来衡量测试集上的困惑度或采样独立的句子。要评估保存的模型,可以使用 evaluate-rnnlm.lua 脚本。
th scripts/evaluate-rnnlm.lua --xplogpath /home/nicholas14/save/rnnlm/gbw:uranus:1466538423:1.t7 --cuda
其中,你应该用你自己的训练模型的路径替换 /home/nicholas14/save/rnnlm/gbw:uranus:1466538423:1.t7。在测试集上进行评估可能需要一段时间,因为它必须使用效率较低的 Linear + SoftMax,因此需要使用非常小的批次大小(这样才能不占用太多内存)。
评估脚本还可以用来从语言模型中生成样本。
th scripts/evaluate-rnnlm.lua --xplogpath /home/nicholas14/save/rnnlm/gbw:uranus:1466790001:1.t7 --cuda --nsample 200 --temperature 0.7
--nsample 标记指定要采样的令牌数量。输入语言模型的第一个令牌是句子开始标记(<S>)。当遇到句子结束标记(</S>)时,模型的隐藏状态将设置为零,这样每个句子都是独立采样的。--temperature 标记可以降低,以使采样更确定性。
<S> There were a number of players in the starting lineup during the season and in recent weeks , in recent years , some fans have been frustrated . </S>
<S> WASHINGTON ( Reuters ) - The government plans to cut greenhouse gases by as much as 12 % on the global economy , a new report said . </S>
<S> One of the most important things about the day was that the two companies had just been guilty of the same nature . </S>
<S> " It has been as much a bit of a public service as a public organisation . </S>
<S> In a nutshell , it 's not only the fate of the economy . </S>
<S> It was last modified at 23.31 GMT on Saturday 22 December 2009 . </S>
<S> He told the newspaper the prosecution had been treating the small boy as " a young man who was playing for a while . </S>
<S> " We are astounded that our employees are not made aware of the risks and risks they are pursuing during this period of time , " he said . </S>
<S> " I had a right to come up with the idea . </S>
多 GPU 训练脚本
正如上一节所观察到的,训练一个只有 250 个隐藏单元的 2 层 LSTM 不会产生最好的生成样本。模型需要的容量远远超过 12GB GPU 的容量。对于参数及其梯度,一个 4x2048 LSTM 模型需要以下内存。
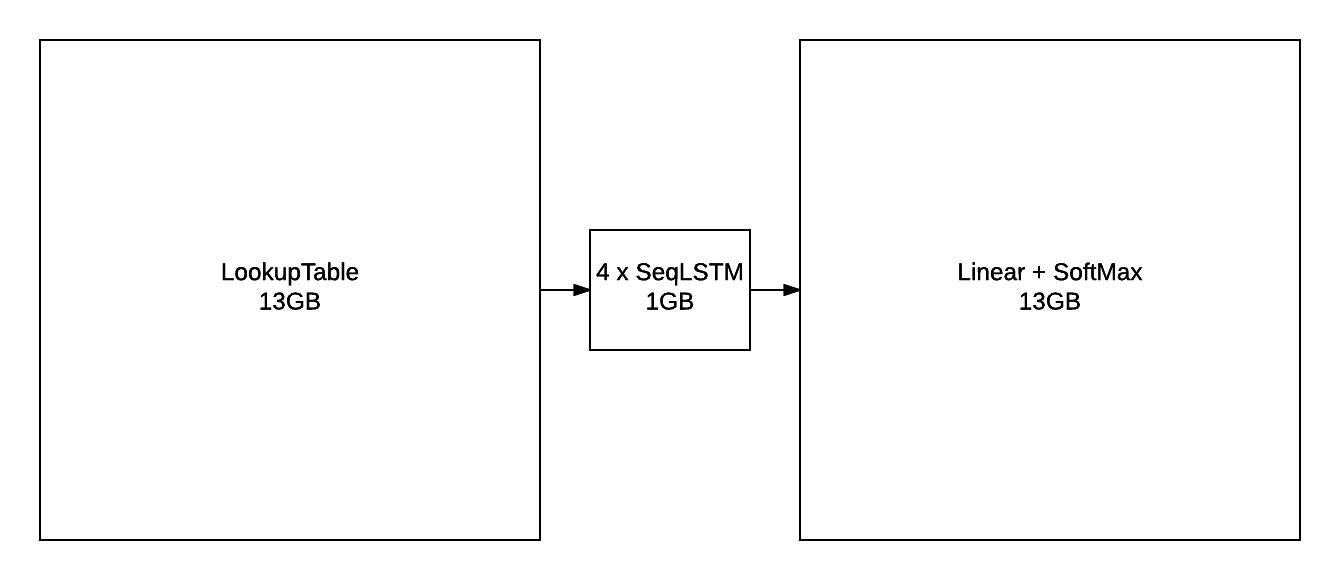
这还不包括不同模块所需的中间缓冲区(在 NCE 部分 中概述)。当然,解决方案是将模型分配到更多 GPU 上。multigpu-nce-rnnlm.lua 脚本就是用来在四个 GPU 上训练语言模型的。
它使用 GPU(我们将其贡献给了 nn)来装饰模块,以便它们的所有操作和内存都驻留在指定设备上。GPU 模块不会将内核执行并行化到不同的 GPU 设备上。但它确实允许我们将大型模型分配到不同的设备上。
对于我们的 LM 来说,输入词嵌入(即 LookupTableMaskZero)和输出层(即 NCEModule)占据了大部分内存。第一个很容易分配。
lm = nn.Sequential()
lm:add(nn.Convert())
-- input layer (i.e. word embedding space)
local concat = nn.Concat(3)
for device=1,2 do
local inputsize = device == 1 and torch.floor(opt.inputsize/2) or torch.ceil(opt.inputsize/2)
local lookup = nn.LookupTableMaskZero(#trainset.ivocab, inputsize)
lookup.maxnormout = -1 -- prevent weird maxnormout behaviour
concat:add(nn.GPU(lookup, device):cuda()) -- input is seqlen x batchsize
end
基本上,嵌入空间被分成两个表。对于一个 2048 个单元的嵌入空间,一半(即 1024 个单元)位于两个设备中的每一个上。我们使用 Concat 在 forward 之后将它们拼接在一起。
对于隐藏层(即 SeqLSTM),我们只需将它们分配到输入层使用的设备上。隐藏层使用的内存很少(每个大约 1GB),所以它们不是问题。我们将它们放在与输入层相同的设备上,因为输出层使用了更多的内存(用于缓冲区)。
local inputsize = opt.inputsize
for i,hiddensize in ipairs(opt.hiddensize) do
local rnn = nn.SeqLSTM(inputsize, hiddensize)
rnn.maskzero = true
local device = i <= #opt.hiddensize/2 and 1 or 2
lm:add(nn.GPU(rnn, device):cuda())
if opt.dropout > 0 then
lm:add(nn.GPU(nn.Dropout(opt.dropout), device):cuda())
end
inputsize = hiddensize
end
lm:add(nn.GPU(nn.SplitTable(1), 3):cuda())
由于 NCEModule 无法像 LookupTableMaskZero 一样轻松地并行化,因此它的分发难度更大。我们的解决方案是提供一个简单的 multicuda() 方法,在不同设备上分发 weight 和 gradWeight。这是通过将权重张量替换为我们自己的张量来实现的:torch.MultiCudaTensor。Lua 没有严格的类型检查系统,因此你可以通过创建一个具有相同方法的 torch.class 表来模拟一个张量。为了节省时间,当前版本的 MultiCudaTensor 只支持 NCEModule 所需的操作。这种方法的优势在于,它只需要对 NCEModule 进行最小的改动,并保持向后兼容性,而无需冗余代码或过度重构。
-- output layer
local unigram = trainset.wordfreq:float()
ncemodule = nn.NCEModule(inputsize, #trainset.ivocab, opt.k, unigram, opt.Z)
ncemodule:reset() -- initializes bias to get approx. Z = 1
ncemodule.batchnoise = not opt.rownoise
-- distribute weight, gradWeight and momentum on devices 3 and 4
ncemodule:multicuda(3,4)
-- NCE requires {input, target} as inputs
lm = nn.Sequential()
:add(nn.ParallelTable()
:add(lm):add(nn.Identity()))
:add(nn.ZipTable())
-- encapsulate stepmodule into a Sequencer
local masked = nn.MaskZero(ncemodule, 1):cuda()
lm:add(nn.GPU(nn.Sequencer(masked), 3, opt.device):cuda())
要重现 [2] 中的结果,请运行以下操作
th examples/multigpu-nce-rnnlm.lua --startlr 0.7 --saturate 300 --minlr 0.001 --cutoff 10 --progress --uniform 0.1 --seqlen 50 --batchsize 128 --trainsize 400000 --validsize 40000 --hiddensize '{2048,2048,2048,2048}' --dropout 0.2 --k 400 --Z 1 --momentum -1
与论文中显著的不同之处如下:
- 我们使用 梯度范数裁剪 [3](裁剪范数为 10)来对抗梯度爆炸和梯度消失;
- 他们使用自适应学习率调度(论文中未指定)。我们从 0.7 的学习率(他们也是从这个值开始的)线性衰减,使其在 300 个 epoch 后达到 0.001;
- 我们使用
k=400个样本,而他们使用k=100。为什么?我没有看到速度有明显下降,所以为什么不呢? - 我们使用
seqlen=50的序列长度进行截断 BPTT。他们使用 100(同样,论文中没有提及)。数据集中的句子平均长度为 27,所以 50 就足够了。
与他们一样,我们在 LSTM 层之间使用 dropout=0.2。最终模型如下所示
nn.Serial @ nn.Sequential {
[input -> (1) -> (2) -> (3) -> output]
(1): nn.ParallelTable {
input
|`-> (1): nn.Sequential {
| [input -> (1) -> (2) -> (3) -> (4) -> (5) -> (6) -> (7) -> (8) -> (9) -> (10) -> (11) -> (12) -> output]
| (1): nn.Convert
| (2): nn.GPU(2) @ nn.Concat {
| input
| |`-> (1): nn.GPU(1) @ nn.LookupTableMaskZero
| |`-> (2): nn.GPU(2) @ nn.LookupTableMaskZero
| ... -> output
| }
| (3): nn.GPU(2) @ nn.Dropout(0.2, busy)
| (4): nn.GPU(1) @ nn.SeqLSTM
| (5): nn.GPU(1) @ nn.Dropout(0.2, busy)
| (6): nn.GPU(1) @ nn.SeqLSTM
| (7): nn.GPU(1) @ nn.Dropout(0.2, busy)
| (8): nn.GPU(2) @ nn.SeqLSTM
| (9): nn.GPU(2) @ nn.Dropout(0.2, busy)
| (10): nn.GPU(2) @ nn.SeqLSTM
| (11): nn.GPU(2) @ nn.Dropout(0.2, busy)
| (12): nn.GPU(3) @ nn.SplitTable
| }
|`-> (2): nn.Identity
... -> output
}
(2): nn.ZipTable
(3): nn.GPU(3) @ nn.Sequencer @ nn.Recursor @ nn.MaskZero @ nn.NCEModule(2048 -> 793471)
}
结果
在具有 2048 个隐藏单元的 4 层 LSTM 上,[1] 在 GBW 测试集上获得了 43.2 的困惑度。在验证集子集(在训练的 100 个 epoch 中,1 个 epoch 为 128 个序列 x 400k 个词/序列)上进行提前停止后,我们的模型能够达到 _40.61_ 的困惑度。
该模型在 4 块 12GB 的 NVIDIA Titan X GPU 上运行。训练大约需要 40GB 的内存,分布在 4 块 GPU 设备上,以及 2-3 周的训练时间。与原始论文一样,我们不使用动量,因为它几乎没有益处,并且需要多 1/2 的内存。
训练速度约为 3800 个词/秒。
学习曲线
下图概述了上述 4x2048 LSTM 模型的学习曲线。该图绘制了模型的 NCE 训练和验证误差,即 NCEModule 输出的误差。测试集误差未绘制,因为在任何 epoch 中进行测试集推理都需要大约 3 个小时,因为测试集推理使用的是 Linear + SoftMax,batchsize=1。
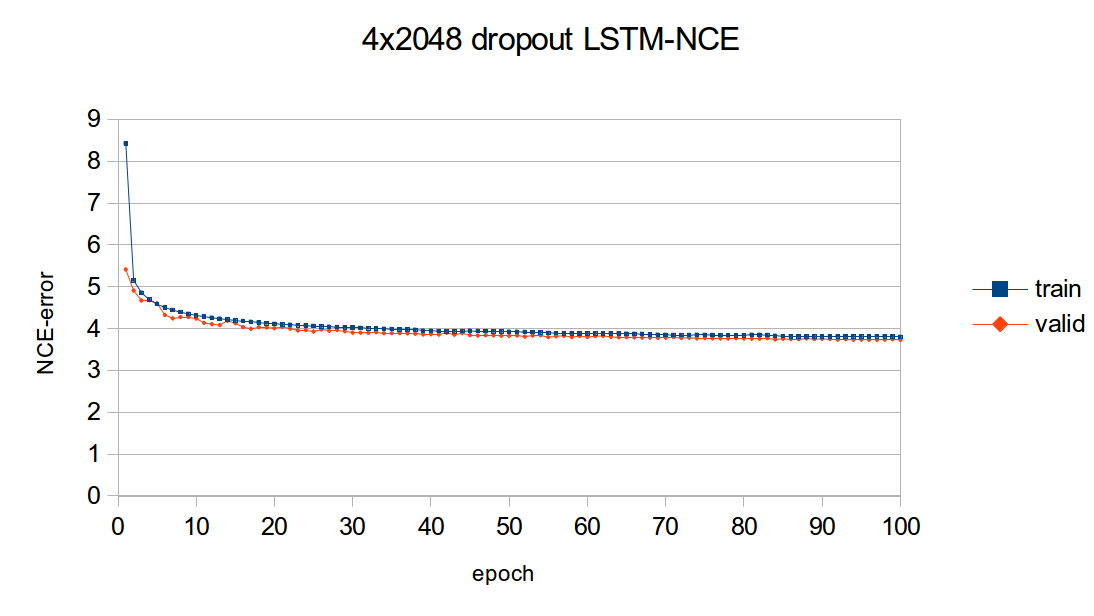
如您所见,大部分学习都在前几个 epoch 中完成。尽管如此,随着训练的进行,训练误差和验证误差始终在不断减小。
下图比较了小型 2x250 LSTM(无 dropout)和大型 4x2048 LSTM(有 dropout)的验证学习曲线(同样,NCE 误差)。
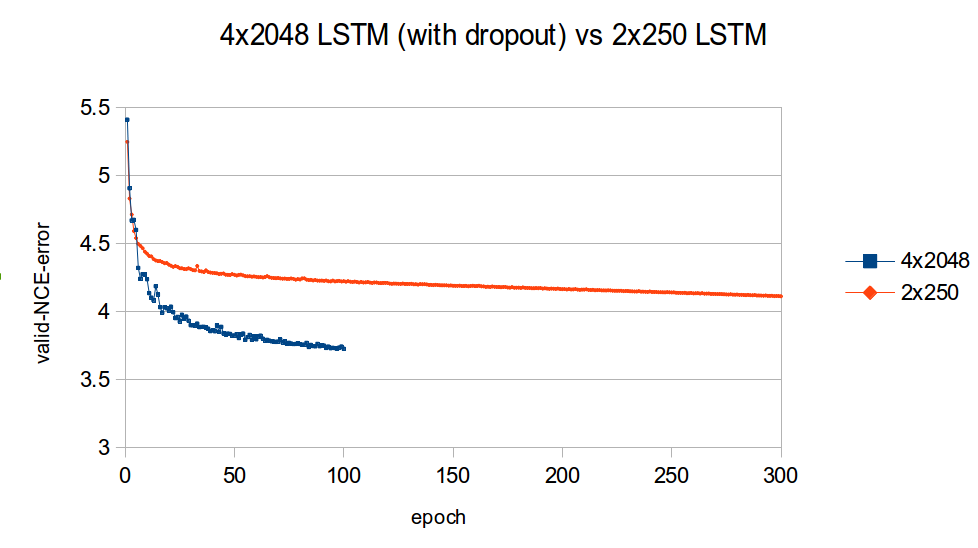
我发现这张图令人印象深刻的是,高容量模型比低容量模型快得多。这清楚地表明了容量在优化大规模语言模型中的重要性。
生成句子
以下是一些从 4 层 LSTM 中独立采样的句子,temperature 为 0.7
<S> The first , for a lot of reasons , is the " Asian Glory " : an American military outpost in the middle of an Iranian desert . </S>
<S> But the first new stage of the project will be a new <UNK> tunnel linking the new terminal with the new terminal at the airport . </S>
<S> The White House said Bush would also sign a memorandum of understanding with Iraq , which will allow the Americans to take part in the poll . </S>
<S> The folks who have campaigned for his nomination know that he is in a fight for survival . </S>
<S> The three survivors , including a woman whose name was withheld and not authorized to speak , were buried Saturday in a makeshift cemetery in the town and seven people were killed in the town of Eldoret , which lies around a dozen miles ( 40 kilometers ) southwest of Kathmandu . </S>
<S> The art of the garden was created by pouring water over a small brick wall and revealing that an older , more polished design was leading to the creation of a new house in the district . </S>
<S> She added : " The club has not made any concession to the club 's fans and was not notified of the fact they had reached an agreement with the club . </S>
<S> The Times has learnt that the former officer who fired the fatal shots must have known about the fatal carnage . </S>
<S> Obama supporters say they 're worried about the impact of the healthcare and energy policies of Congress . </S>
<S> Not to mention the painful changes to the way that women are treated in the workplace . </S>
<S> The dollar stood at 14.38 yen ( <UNK> ) and <UNK> Swiss francs ( <UNK> ) . </S>
<S> The current , the more intractable <UNK> , the <UNK> and the <UNK> about a lot of priorities . </S>
<S> The job , which could possibly be completed in 2011 , needs to be approved in a new compact between the two companies . </S>
<S> " The most important thing for me is to get back to the top , " he said . </S>
<S> It was a one-year ban and the right to a penalty . </S>
<S> The government of president Michelle Bachelet has promised to maintain a " strong and systematic " military presence in key areas and to tackle any issue of violence , including kidnappings . </S>
<S> The six were scheduled to return to Washington on Wednesday . </S>
<S> " It 's a ... mistake , " he said . </S>
<S> The government 's offensive against the rebels and insurgents has been criticized by the United Nations and UN agencies . </S>
<S> " Our <UNK> model is not much different from many of its competitors , " said Richard Bangs , CEO of the National Center for Science in the Public Interest in Chicago . </S>
<S> He is now a large part of a group of young people who are spending less time studying and work in the city . </S>
<S> He said he was confident that while he and his wife would have been comfortable working with him , he would be able to get them to do so . </S>
<S> The summer 's financial meltdown is the worst in decades . </S>
<S> It was a good night for Stuart Broad , who took the ball to Ravi Bopara at short leg to leave England on 88 for five at lunch . </S>
<S> And even for those who worked for them , almost everything was at risk . </S>
<S> The new strategy is all part of a stepped-up war against Taliban and al-Qaida militants in northwest Pakistan . </S>
<S> The governor 's office says the proposal is based on a vision of an outsider in the town who wants to preserve the state 's image . </S>
<S> " The fact that there is no evidence to support the claim made by the government is entirely convincing and that Dr Mohamed will have to be detained for a further two years , " he said . </S>
<S> The country 's tiny nuclear power plants were the first to use nuclear technology , and the first such reactors in the world . </S>
<S> " What is also important about this is that we can go back to the way we worked and work and fight , " he says . </S>
<S> And while he has been the star of " The Wire " and " The Office , " Mr. Murphy has been a careful , intelligent , engaging competitor for years . </S>
<S> On our return to the water , we found a large abandoned house . </S>
<S> The national average for a gallon of regular gas was $ 5.99 for the week ending Jan . </S>
<S> The vote was a rare early start for the contest , which was held after a partial recount in 26 percent of the vote . </S>
<S> The first one was a show of force by a few , but the second was an attempt to show that the country was serious about peace . </S>
<S> It was a little more than half an hour after the first reports of a shooting . </S>
<S> The central bank is expected to cut interest rates further by purchasing more than $ 100 billion of commercial paper and Treasuries this week . </S>
<S> Easy , it 's said , to have a child with autism . </S>
<S> He said : " I am very disappointed with the outcome because the board has not committed itself . </S>
<S> " There is a great deal of tension between us , " said Mr C. </S>
<S> The odds that the Fed will keep its benchmark interest rate unchanged are at least half as much as they were at the end of 2008 . </S>
<S> For them , investors have come to see that : a ) the government will maintain a stake in banks and ( 2 ) the threat of financial regulation and supervision ; and ( 3 ) it will not be able to raise enough capital from the private sector to support the economy . </S>
<S> The court heard he had been drinking and drank alcohol at the time of the attack . </S>
<S> " The whole thing is quite a bit more intense . </S>
<S> This is a very important project and one that we are working closely with . </S>
<S> " We are confident that in this economy and in the current economy , we will continue to grow , " said John Lipsky , who chaired the IMF 's board of governors for several weeks . </S>
<S> The researchers said they found no differences among how men drank and whether they were obese . </S>
<S> Even though there are many brands that have low voice and no connection to the Internet , the iPhone is a great deal for consumers . </S>
<S> The £ 7m project is a new project for the city of Milton Keynes and aims to launch a new challenge for the British Government . </S>
<S> But he was not without sympathy for his father . </S>
语法看起来相当合理,特别是与之前从 单 GPU 2x250 LSTM 获得的结果相比。但是,在某些情况下,语义,即词语的含义,并不那么好。例如,句子
<S> Easy , it 's said , to have a child with autism . </S>
至少对我来说,用 Not easy 替换 Easy 更有意义。
另一方面,像这样的句子展示了良好的语义
<S> The government of president Michelle Bachelet has promised to maintain a " strong and systematic " military presence in key areas and to tackle any issue of violence , including kidnappings . </S>`.
米歇尔·巴切莱特 实际上是智利的总统。在她早年,她也被 军人绑架,所以她对绑架问题强硬是有道理的。
这是一个奇怪语义的例子
<S> Even though there are many brands that have low voice and no connection to the Internet , the iPhone is a great deal for consumers . </S>
关于 load voice 的第一部分对我来说毫无意义。而且我无法理解,为什么会有 许多与互联网无关的品牌与 iPhone 对消费者来说是一笔好交易有关。当然,所有这些句子都是独立生成的,因此 LM 需要学会即时生成含义。这很困难,因为生成句子时没有上下文。
无论如何,我对结果感到很满意,因为它们绝对是我迄今为止看到的最自然的合成句子之一。
未来工作
我目前正在研究一个基于一个月 reddit.com 数据的语言建模数据集。每个序列基本上都是一个 reddit 提交,包括一个 TITLE、SELFTEXT(或 URL)、SCORE、AUTHOR 和一个 COMMENTS 线程。这些序列比构成 GBW 数据集的句子(平均 26 个词符)长得多(平均 205 个词符)。训练仍在进行中,但是为了引起您的兴趣,这是一个生成的示例(为了清晰起见,添加了缩进和换行符)
<SUBMISSION>
<AUTHOR> http://www.reddit.com/u/[deleted] </AUTHOR>
<SCORE> 0 </SCORE>
<TITLE>
[ WP ] You take a picture of a big bang .
You discover an alien that lives in the center of the planet in an unknown way .
You can say " what the fuck is that ? "
</TITLE>
<COMMENTS>
<CoMMeNT>
<ScoRE> 2 </ScoRE>
<AuTHoR> http://www.reddit.com/u/Nev2k </AuTHoR>
<BodY>
I have a question .
When i was younger , my parents had a house that had a living room in it .
One that was only a small portion of an entire level .
This was a month before i got my money .
If i was living in a house with a " legacy " i would make some mistakes .
When i was a child , i did n't know how to do shit about the house .
My parents got me into my own house and i never found a place to live .
So i decide to go to college .
I was so freaked out , i didnt have the drive to see them .
I never had a job , i was n't going anywhere .
I was so happy .
I knew i was going to be there .
I gave myself a job and my parents came .
That 's when i realized that i was in the wrong .
So i started to go .
I couldnt decide how long i wanted to live in this country .
I was so excited about the future .
I had a job .
I saved my money .
I did n't have a job .
I went to a highschool in a small town .
I had a job .
A job .
I did n't know what to do .
I was terrified of losing my job .
So i borrowed my $ 1000 in an hour .
I could n't afford to pay my rent .
I was so low on money .
I had my parents and i got into a free college .
I got in touch with my parents .
All of my friends were dead .
I was still with my family for a week .
I became a good parent .
I was a good choice .
When i got on my HSS i was going to go to my parents ' house .
I started to judge my parents .
I had a minor problem .
My parents .
I was so fucking bad .
My sister had a voice that was very loud .
I 'm sure my cousins were in a place where i could just hear my voice .
I felt like i was supposed to be angry .
I was so angry .
To cope with this .
My dad and i were both on break and i felt so alone .
I got unconscious and my mum left .
When I got to college , i was back in school .
I was a good kid .
I was happy .
And I told myself I was ready .
I told my parents .
They always talked about how they were going to be a good mom , and that I was going to be ready for that .
They always wanted to help me .
I did n't know what to do .
I had to .
I tried to go back to my dad , because I knew a lot about my mom .
I loved her .
I cared about her .
We cared for our family .
The time together was my only relationship .
I loved my heart .
And I hated my mother .
I chose it .
I cried . I cried . I cried . I cried . I cried . I cried . I cried .
The tears were gone .
I cried . I cried . I cried . I cried . I cried . I cried . I cried . I cried . I cried . I cried .
I do n't know how to do it .
I do n't know how to deal with it .
I ca n't feel my emotions .
I ca n't get out of bed .
I ca n't sleep .
I ca n't tell my friends .
I just need to leave .
I want to leave .
I hate myself .
I hate feeling like I 'm being selfish .
I feel like I 'm not good enough anymore .
I need to find a new job .
I hate that I have to get my shit together .
I love my job .
I 'm having a hard time .
Why do I need to get a job ?
I have no job .
I have n't been feeling good lately .
I feel like I 'm going to be so much worse in the long run .
I feel so alone .
I ca n't believe I 'm so sad about going through my entire life .
</BodY>
<AuTHoR> http://www.reddit.com/u/Scarbarella </AuTHoR>
</CoMMeNT>
</COMMENTS>
<SUBREDDIT> http://www.reddit.com/r/offmychest </SUBREDDIT>
<SELFTEXT>
I do n't know what to do anymore .
I feel like I 'm going to die and I 'm going to be sick because I have no more friends .
I do n't know what to do about my depression and I do n't know where to go from here .
I do n't know how I do because I know I 'm scared of being alone .
Any advice would be appreciated .
Love .
</SELFTEXT>
</SUBMISSION>
这个特定的示例有点令人沮丧,但这可能仅仅是 offmychest 子版块的性质。在开头 <SUBMISSION> 词符的条件下,这个生成的序列虽然不完美,但却令人难以置信地人性化。读完评论,我感觉自己像是在读一个由一个真实的人(有点精神分裂)写的故事。模拟人类创造力的能力是我对使用 reddit 数据进行语言建模如此感兴趣的原因之一。
一个不太令人沮丧的示例如下,它涉及到 命运 游戏
<SUBMISSION>
<SUBREDDIT> http://www.reddit.com/r/DestinyTheGame </SUBREDDIT>
<TITLE>
Does anyone have a link to the Destiny Grimoire that I can use to get my Xbox 360 to play ?
</TITLE>
<COMMENTS>
<CoMMeNT>
<AuTHoR> http://www.reddit.com/u/CursedSun </AuTHoR>
<BodY>
I 'd love to have a weekly reset .
</BodY>
<ScoRE> 1 </ScoRE>
</CoMMeNT>
</COMMENTS>
<SCORE> 0 </SCORE>
<SELFTEXT>
I have a few friends who are willing to help me out .
If I get to the point where I 'm not going to have to go through all the weekly raids , I 'll have to " complete " the raid .
I 'm doing the Weekly strike and then doing the Weekly ( and hopefully also the Weekly ) on Monday .
I 'm not planning to get the chest , but I am getting my first exotic that I just got done from my first Crota raid .
I 'm not sure how well it would work for the Nightfall and Weekly , but I do n't want to loose my progress .
I 'd love to get some other people to help me , and I 'm open to all suggestions .
I have a lot of experience with this stuff , so I figured it 's a good idea to know if I 'm getting the right answer .
I 'm truly sorry for the inconvenience .
</SELFTEXT>
<AUTHOR> <OOV> </AUTHOR>
</SUBMISSION>
对于那些不熟悉这款游戏的人来说,像 Grimoire、每周重置、raid、Nightfall 突袭、异域 和 克罗塔突袭 这样的术语可能看起来很奇怪。但这些都是游戏词汇的一部分。
这个特定模型(一个带有 dropout 的 4x1572 LSTM)只反向传播了 50 个时间步长。我希望看到 COMMENTS 能够真正回答由 TITLE 和 SELFTEXT 提出的问题。这是一个非常困难的语义问题,我希望 reddit 数据集能够帮助解决。在我的下一篇 Torch 博客文章中将有更多内容。
参考资料
- A Mnih, YW Teh, 用于训练神经概率语言模型的快速简单算法
- B Zoph, A Vaswani, J May, K Knight, 用于大型 RNN 词汇表的简单快速噪声对比估计
- R Pascanu, T Mikolov, Y Bengio, 关于训练循环神经网络的困难
- S Hochreiter, J Schmidhuber, 长短期记忆
- A Graves, A Mohamed, G Hinton, 使用深度循环神经网络进行语音识别
- K Greff, RK Srivastava, J Koutník, LSTM:一个探索空间的奥德赛
- C Chelba, T Mikolov, M Schuster, Q Ge, T Brants, P Koehn, T Robinson, 十亿词基准测试用于衡量统计语言建模的进展
- A Graves, 使用循环神经网络生成序列,表 1