可视注意力的循环模型
在这篇博文中,我想讨论我们在 Element-Research 如何实现 [1] 中描述的循环注意力模型 (RAM)。我们不仅能够复现论文,还在这个过程中创建了一堆模块化代码。你可以使用这个 训练脚本 在 MNIST 数据集上复现 RAM。我们将在本文中使用该脚本的片段。然后,你可以使用 评估脚本 评估你训练的模型。
该论文描述了一个可以应用于图像分类数据集的 RAM。该模型的设计方式使其拥有输入图像的带宽受限传感器。例如,如果输入图像大小为 28x28(高度 x 宽度),则 RAM 在任何给定时间步长可能只能感知大小为 8x8 的区域。这些小感知区域被称为 *瞥见*。
空间瞥见
实际上,论文中的瞥见传感器比我们上面描述的要稍微复杂一些,但仍然很简单。为了与 Torch7 的 nn 包的模块化精神保持一致,我们创建了一个 SpatialGlimpse 模块。
module = nn.SpatialGlimpse(size, depth, scale)
基本上,如果你给它一个图像,比如经典的 3x512x512 Lenna 图像

然后你对其运行以下代码
require 'dpnn'
require 'image'
img = image.lena()
loc = torch.Tensor{0,0} -- 0.0 is the center of the image
sg = nn.SpatialGlimpse(64, 3, 2)
output = sg:forward{img, loc}
print(output:size()) -- 9 x 64 x 64
-- unroll the glimpse onto its different depths
outputs = torch.chunk(output, 3)
display = image.toDisplayTensor(outputs)
image.save("glimpse-output.png", display)
你最终将得到以下(展开的)瞥见

虽然输入是一个 3x512x512 图像(786432 个标量),但输出非常小:9x64x64(36864 个标量),大约是原始图像大小的 5%。由于这里的瞥见具有 depth=3(即它使用 3 个补丁),因此每个后续补丁都是先前补丁大小的 scale 倍。所以我们最终得到一个具有较小区域的高分辨率补丁,以及越来越低分辨率(即下采样)的更大区域补丁。这与我们人类的注意力机制如何可能运作有着惊人的相似之处。通常情况下,我们可以清晰地看到我们注意力集中之处的细节,同时仍然保持着对周围环境的模糊感知。
虽然对于复现这篇论文来说并不必要,但 SpatialGlimpse 也可以部分反向传播。虽然可以获得相对于 img 张量的梯度,但相对于 location(即瞥见的 x,y 坐标)的梯度将为零。这是因为瞥见操作不能相对于 location 进行微分。这让我们来到了注意力模型的主要困难之处:我们如何教会网络在正确的 locations 上瞥见呢?
REINFORCE 算法
一些注意力模型使用完全可微分的注意力机制,例如最近的 DRAW 论文 [2]。但 RAM 模型使用不可微分的注意力机制。具体来说,它使用 REINFORCE 算法 [3]。该算法允许人们通过强化学习训练随机单元。
REINFORCE 算法非常强大,因为它可以用来优化随机单元(以输入为条件),使它们最小化目标函数(即奖励函数)。*与反向传播 [4] 不同,这个目标函数不需要是可微分的*。
RAM 模型使用 REINFORCE 算法训练 locator 网络
-- actions (locator)
locator = nn.Sequential()
locator:add(nn.Linear(opt.hiddenSize, 2))
locator:add(nn.HardTanh()) -- bounds mean between -1 and 1
locator:add(nn.ReinforceNormal(2*opt.locatorStd)) -- sample from normal, uses REINFORCE learning rule
locator:add(nn.HardTanh()) -- bounds sample between -1 and 1
locator:add(nn.MulConstant(opt.unitPixels*2/ds:imageSize("h")))
输入是前一个循环隐藏状态 h[t-1]。在训练期间,输出从具有固定标准差的正态分布中采样。均值通过仿射变换(即 Linear 模块)以 h[t-1] 为条件。在评估期间,而不是从分布中采样,输出被设置为输入,即均值。
ReinforceNormal 模块为正态分布实现了 REINFORCE 算法。与大多数 Modules 不同,ReinforceNormal 在调用 backward 时忽略 gradOutput。这是因为它所包含的单元实际上是随机的。那么它在调用 backward 时如何生成 gradInputs 呢?它使用 REINFORCE 算法,该算法要求定义奖励函数。论文使用的奖励非常简单,但不可微分(公式 1)
R = I(y=t)
其中 R 是原始奖励,I(x) 在 x 为真时为 1,否则为 0(参见 指示函数),y 是预测的类别,t 是目标类别。或者用 Lua 表示
R = (y==t) and 1 or 0
REINFORCE 算法要求我们对分布的概率密度或质量函数(PDF/PMF)相对于参数进行微分。因此,给定以下变量
f:正态概率密度函数x:采样值(即ReinforceNormal.output)u:均值(ReinforceNormal的input)s:标准差(ReinforceNormal.stdev)
对数正态相对于均值 u 的导数为
d ln(f(x,u)) (x - u)
------------ = -------
d u s^2
那么 d ln(f(x,u,s) / d u 如何与奖励相适应呢?嗯,为了获得奖励 R 相对于输入 u 的梯度,我们应用以下公式(公式 2,即 REINFORCE 算法)
d R d ln(f(x,u))
--- = a * (R - b) * --------------
d u d u
其中
a(alpha)只是一个缩放因子,就像学习率一样;而b是一个基线奖励,用于减少梯度的方差。f是 PMF/PDFu是你想要获得梯度的参数x是采样值。
在论文中,他们将 b 设置为期望奖励 E[R]。他们通过将 b 设为模型的(条件独立)参数来近似期望值。对于每个示例,R 和 b 之间的均方误差通过反向传播最小化。这样做的好处是,与将 b 设为 R 的移动平均值相比,*基线奖励 b 的学习速度与模型其他部分相同*。
我们决定在 VRClassReward 准则中实现 reward = a * (R - b),该准则还实现了论文中的方差减少分类奖励函数(公式 1)
vcr = nn.VRClassReward(module [, scale, criterion])
nn 包主要构建用于反向传播,因此我们必须找到一种不太 hack 的方法来将 reward 广播到不同的 Reinforce 模块。我们通过让准则将 module 作为参数,并添加 Module:reinforce(reward) 方法来实现这一点。后者允许 Reinforce 模块(如 ReinforceNormal)保留准则的广播 reward 以供日后使用。日后就是当调用 backward 并且 Reinforce 模块计算 gradInput(即 d R / d U)时使用 REINFORCE 算法(公式 2)。然后 nn 就很高兴了,因为它有了 gradInput,它就可以从 Reinforce 模块继续向其前驱进行反向传播。
因此,总而言之,如果你可以对 PMF/PDF 相对于其参数进行微分,那么你就可以在其上使用 REINFORCE 算法。我们已经实现了用于分类和伯努利分布的模块
循环注意力模型
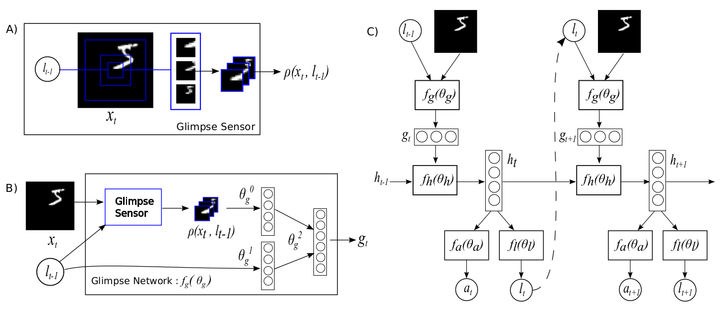
好的,我们已经讨论了瞥见模块和 REINFORCE 算法,现在我们来谈谈循环注意力模型。我们可以将该模型划分为其各自的组件
位置传感器。它的输入是当前瞥见位置的 x、y 坐标,因此网络知道它在每个时间步长*在哪里*看
locationSensor = nn.Sequential()
locationSensor:add(nn.SelectTable(2))
locationSensor:add(nn.Linear(2, opt.locatorHiddenSize))
locationSensor:add(nn[opt.transfer]())
瞥见传感器是它*在看什么*
glimpseSensor = nn.Sequential()
glimpseSensor:add(nn.DontCast(nn.SpatialGlimpse(opt.glimpsePatchSize, opt.glimpseDepth, opt.glimpseScale):float(),true))
glimpseSensor:add(nn.Collapse(3))
glimpseSensor:add(nn.Linear(ds:imageSize('c')*(opt.glimpsePatchSize^2)*opt.glimpseDepth, opt.glimpseHiddenSize))
glimpseSensor:add(nn[opt.transfer]())
瞥见网络是瞥见和位置传感器通过隐藏层混合以形成循环神经网络 (RNN) 的输入层的地方
glimpse = nn.Sequential()
glimpse:add(nn.ConcatTable():add(locationSensor):add(glimpseSensor))
glimpse:add(nn.JoinTable(1,1))
glimpse:add(nn.Linear(opt.glimpseHiddenSize+opt.locatorHiddenSize, opt.imageHiddenSize))
glimpse:add(nn[opt.transfer]())
glimpse:add(nn.Linear(opt.imageHiddenSize, opt.hiddenSize))
RNN 是瞥见网络和循环层结合的地方。rnn 模块的输出是隐藏状态 h[t],其中 t 索引时间步长。我们使用了 rnn 包来构建它
-- rnn recurrent layer
recurrent = nn.Linear(opt.hiddenSize, opt.hiddenSize)
-- recurrent neural network
rnn = nn.Recurrent(opt.hiddenSize, glimpse, recurrent, nn[opt.transfer](), 99999)
我们已经在上面看到了定位器网络,但这里再次列出
-- actions (locator)
locator = nn.Sequential()
locator:add(nn.Linear(opt.hiddenSize, 2))
locator:add(nn.HardTanh()) -- bounds mean between -1 and 1
locator:add(nn.ReinforceNormal(2*opt.locatorStd)) -- sample from normal, uses REINFORCE learning rule
locator:add(nn.HardTanh()) -- bounds sample between -1 and 1
locator:add(nn.MulConstant(opt.unitPixels*2/ds:imageSize("h")))
定位器的任务是根据前一个隐藏状态 h[t-1],即 rnn 的前一个输出,来采样下一个位置 l[t](或动作)。对于第一步,我们使用 h[0] = 0(一个全零张量)作为前一个隐藏状态。我们还应提醒您注意 opt.unitPixels 变量,因为它非常重要,并且在论文中没有说明。这个变量基本上概述了每个瞥见的中心相对于中心的边缘可以到达多远(以像素为单位)。因此,值为 13(默认值)意味着瞥见的中心可以位于第 2 个和第 27 个像素之间的任何位置(对于 1x28x28 MNIST 示例)。因此,角落的瞥见将比 opt.unitPixels = 14 时具有更少的零填充值。
我们需要将 rnn 和 locator 封装到一个模块中,该模块可以捕捉到 RAM 模型的本质。因此,我们决定实现一个模块,该模块以完整图像作为输入,并输出隐藏状态序列 h。顾名思义,这个模块是一个通用的 RecurrentAttention 模块
attention = nn.RecurrentAttention(rnn, locator, opt.rho, {opt.hiddenSize})
该模型非常通用,你可以把它与 LSTM 模块以及不同的 glimpses 或 locator 模块一起使用。只要这些模块分别保留相同的 {input, action} -> output 接口(glimpse)并使用 REINFORCE 算法(locator)即可。当然。
接下来,我们通过在 RecurrentAttention 模块之上堆叠一个分类器来构建一个 agent。分类器的输入是最后一个隐藏状态 h[T],其中 T 是总时间步数(即需要采取的 glimpses 数)。
-- model is a reinforcement learning agent
agent = nn.Sequential()
agent:add(nn.Convert(ds:ioShapes(), 'bchw'))
agent:add(attention)
-- classifier :
agent:add(nn.SelectTable(-1))
agent:add(nn.Linear(opt.hiddenSize, #ds:classes()))
agent:add(nn.LogSoftMax())
你可能还记得 REINFORCE 算法需要一个基线奖励 b 吗?这就是它发生的地方(是的,它需要一点 nn 功夫)。
-- add the baseline reward predictor
seq = nn.Sequential()
seq:add(nn.Constant(1,1))
seq:add(nn.Add(1))
concat = nn.ConcatTable():add(nn.Identity()):add(seq)
concat2 = nn.ConcatTable():add(nn.Identity()):add(concat)
-- output will be : {classpred, {classpred, basereward}}
agent:add(concat2)
此时,模型已准备好进行训练。 agent 实例实际上是论文中详细描述的 RAM 模型。
训练
之后,训练非常简单。可以使用默认超参数启动脚本。应该运行 1-2 次才能找到一个能够重现论文中 MNIST 测试结果的验证最小值。我们仍在努力重现 Translated 和 Cluttered MNIST 结果。
结果
在论文中,他们在 MNIST 上使用 7 个 glimpses 实现了 1.07% 的错误率。我们在经过 853 轮训练后(当然是在验证集上提前停止)获得了 0.85% 的错误率。这里有一些 glimpse 序列。注意,第一帧从同一个位置开始。

这就是模型对这些序列的看法。
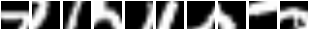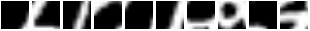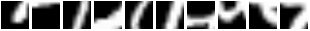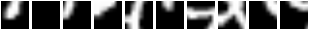
所以基本上,REINFORCE 做了一件很好的工作,它教会了模块如何在给定不同输入的情况下将注意力集中到不同的区域。一个失败模式(坏)是看到模型做这件事。

在这种特殊情况下, opt.unitPixels 被设置为 6 而不是 12(因此注意力被限制在图像中心的较小区域)。你不想让这种情况发生,因为它意味着注意力与输入条件无关(即愚蠢)。
以下是一些 Translated MNIST 数据集的结果。

对于此数据集,图像的大小为 1x60x60,其中每个图像包含一个随机放置的 1x28x28 MNIST 数字。 3x12x12 glimpse 使用深度为 3 的尺度,其中每个连续的补丁的高度和宽度都是前一个补丁的两倍。在经过 683 轮训练后,使用 7 个 glimpses,我们在 Translated MNIST 数据集上获得了 0.92% 的错误率。论文分别在 6 个和 8 个 glimpses 下获得了 1.22% 和 1.2% 的错误率。用于获得这些结果的精确命令
th examples/recurrent-visual-attention.lua --cuda --dataset TranslatedMnist --unitPixels 26 --learningRate 0.001 --glimpseDepth 3 --maxTries 200 --stochastic --glimpsePatchSize 12
注意:你可以使用 评估脚本 评估你的模型。它将生成一个 glimpse 序列样本并打印测试集的混淆矩阵结果。
结论
这篇博客讨论了使用 REINFORCE 算法实现视觉注意力的循环模型的具体示例。REINFORCE 算法非常强大,因为它可以通过强化学习来学习不可微分的标准。然而,与许多强化学习算法一样,它需要很长时间才能收敛。尽管如此,正如这里和原始论文中所证明的那样,训练模型来学习将注意力集中在何处的能力可以显著提高性能。
参考文献
- Volodymyr Mnih, Nicolas Heess, Alex Graves, Koray Kavukcuoglu, 视觉注意力的循环模型,NIPS 2014
- Gregor, Karol, et al., DRAW:一种用于图像生成的循环神经网络,Arxiv 2015
- Williams, Ronald J., 用于连接主义强化学习的简单统计梯度跟随算法,机器学习 8.3-4 (1992): 229-256.
- Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. 通过误差反向传播学习内部表示,No. ICS-8506