训练和调查残差网络
这篇文章由来自 Facebook AI Research 的 Sam Gross 和来自 CornellTech 的 Michael Wilber 合著。
在这篇博文中,我们实现了深度残差网络 (ResNets),并从模型选择和优化角度调查了 ResNets。我们还讨论了多 GPU 优化以及训练 ResNets 的最佳工程实践。最后,我们将 ResNets 与 GoogleNet 和 VGG 网络进行比较。
我们在 GitHub 上发布了训练代码,以及预训练模型供下载,并附带了在您自己的数据集上进行微调的说明。
我们发布的预训练模型比原始论文中的模型具有更高的准确性。
介绍
在去年年底,微软亚洲研究院发布了一篇名为“用于图像识别的深度残差学习”的论文,作者为何恺明、张祥雨、任少卿和孙剑。该论文在图像分类和检测方面取得了最先进的结果,赢得了 ImageNet 和 COCO 比赛。
论文本身的核心思想很简单也很优雅。他们采用标准的前馈卷积网络,并添加跳跃连接,每次绕过 (或捷径) 一些卷积层。每个旁路都会产生一个残差块,其中卷积层预测一个残差,该残差将添加到块的输入张量。
下图显示了一个示例残差块。
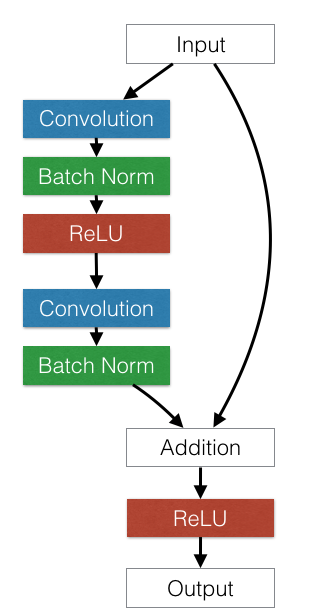
深度前馈卷积网络往往会遇到优化困难。超过一定深度后,添加额外的层会导致更高的训练误差和更高的验证误差,即使使用批量归一化也是如此。ResNet 论文的作者认为,这种欠拟合不太可能是由梯度消失引起的,因为即使在使用批量归一化的网络中也会出现这种困难。残差网络架构通过添加捷径连接来解决这个问题,这些捷径连接与卷积层的输出相加。
这篇文章提供了一些数据点,供那些试图从优化角度更详细地了解残差网络的人使用。它还调查了某些设计决策对所得网络有效性的贡献。
在论文发表在 Arxiv 上之后,我们这两位作者都独立地开始调查和复制论文的结果。在了解了彼此的努力之后,我们决定共同撰写一篇结合我们经验的文章。
消融研究(在 CIFAR-10 上)
当试图理解诸如残差网络之类的复杂机制时,在更大规模上进行探索性研究(例如在 ImageNet 数据集上)可能会很麻烦,因为训练完整模型需要几天才能收敛。相反,在较小的数据集上运行消融研究通常很有帮助,以独立地衡量模型每个方面的影响。这样,我们就可以快速确定在进一步开发过程中最需要关注的研究部分。快速周转时间和持续验证在设计完整系统时非常有用,因为在最后阶段,被忽视的细节往往会给你带来麻烦。
对于这些实验,我们使用 CIFAR-10 数据集复制了残差网络论文的第 4.2 节。在这种情况下,一个具有 20 层的小型残差网络在 Amazon EC2 g2.2xlarge 实例上训练 200 个 epochs 大约需要 8 个小时才能收敛。一个较大的 110 层网络需要 24 个小时。这仍然很长时间,但阻止收敛的关键错误通常会立即显现出来,因为如果代码没有错误,训练损失应该会很快下降(在训练开始后的几分钟内)。
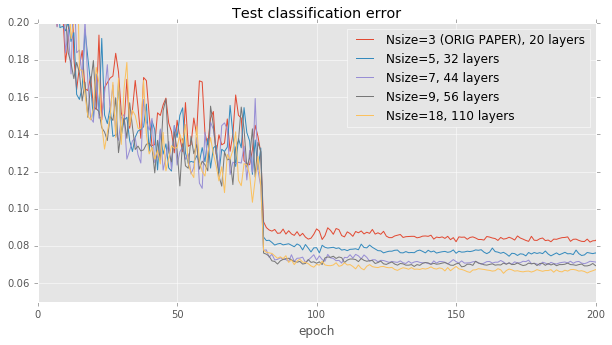
模型深度的影响。残差网络论文为比较提供了自然起点:论文中的图 6 只是测量了准确性与网络深度的关系。为了重现此图,我们在保持学习率策略和构建块架构不变的情况下,将网络中的层数在 20 到 110 之间变化。我们的结果与论文中的结果非常接近:准确性与模型大小有很好的相关性,但在大约 40 层之后趋于平稳。
残差块架构。
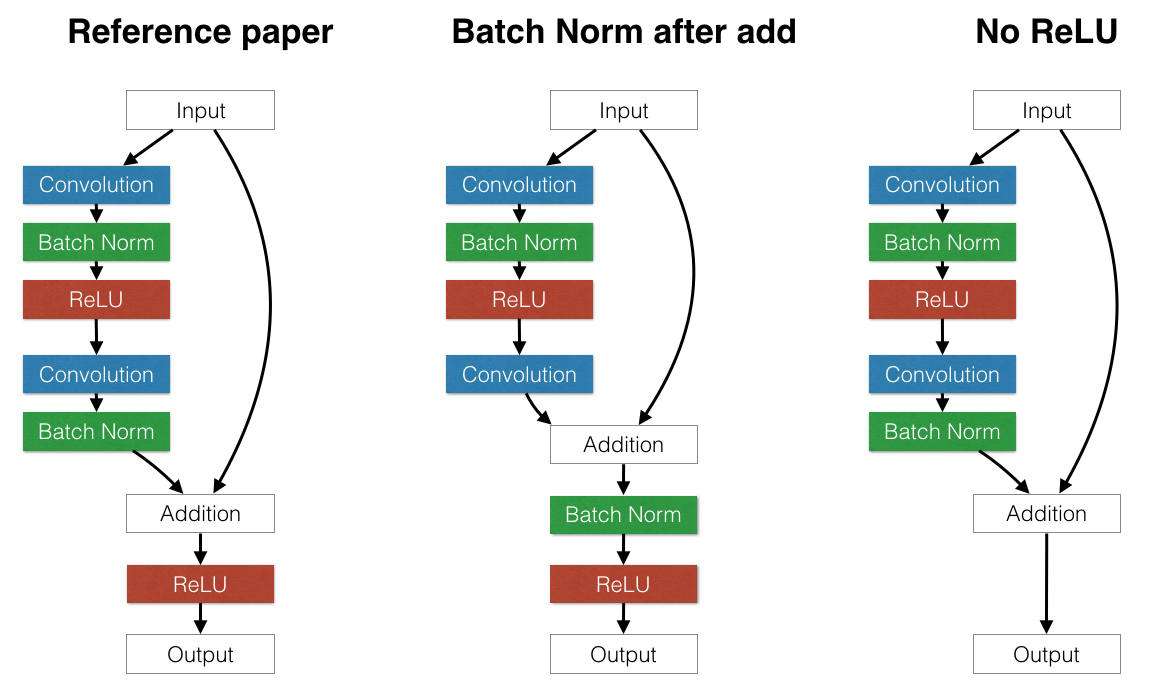
在验证了我们的结果与原始论文非常接近之后,我们开始考虑略微不同的残差块架构的影响,以检验模型的假设。例如
-
将批量归一化放在每个残差块末尾的加法之后还是之前更好?如果批量归一化放在加法之后,它将对整个块的输出进行归一化。这可能是有益的。但是,这也迫使每个跳跃连接来扰乱输出。这可能会出现问题:有一些路径允许数据通过几个连续的批量归一化层而不进行任何其他处理。每个批量归一化层都会应用其自己的独立失真,这会加剧原始输入。这会产生有害影响:我们发现,将批量归一化放在加法之后会显着损害 CIFAR 上的测试误差,这与原始论文的建议一致。
-
上述结果似乎表明,避免更改仅通过身份连接传递的数据非常重要。我们可以将这种理念更进一步:我们是否应该删除每个残差块末尾的 ReLU 层?ReLU 层也会扰乱通过身份连接传递的数据,但与批量归一化不同,ReLU 的幂等性意味着,数据通过一个 ReLU 还是三十个 ReLU 并不重要。当我们删除每个构建块末尾的 ReLU 层时,我们观察到与论文建议的将 ReLU 放置在加法之后的方案相比,测试性能略有提高。但是,这种影响很小。需要更多探索。
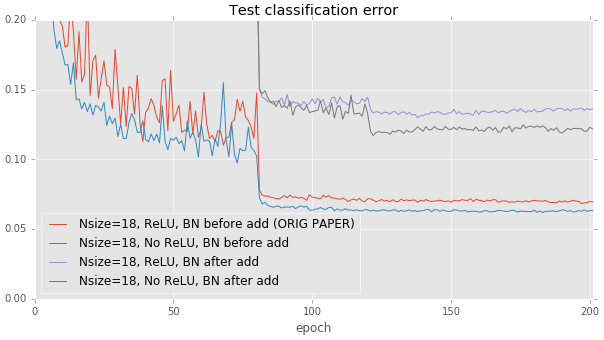
这些结果是在更深的 110 层模型上运行的。这种影响在浅层的 20 层基线模型上要小得多。
备用优化器。在进行超参数搜索时,尝试比使用动量的普通 SGD 更高级的优化策略通常会有所回报。做出细微假设的更高级优化器可能会缩短训练时间,但它们可能难以训练这些非常深的模型。在我们的实验中,我们将 SGD+动量(如原始论文中使用的那样)与 RMSprop、Adadelta 和 Adagrad 进行了比较。它们中的许多似乎在最初收敛得更快(见下图中的训练曲线),但最终,SGD+动量的测试误差比第二好的策略低 0.7%。
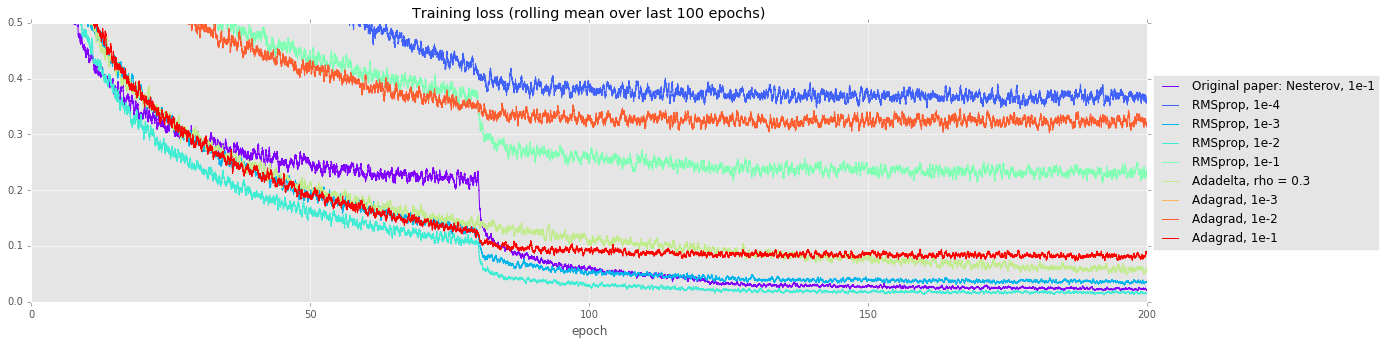
| 求解器 | 测试误差 |
|---|---|
| Nsize=18,原始论文:Nesterov,1e-1 | 0.0697 |
| Nsize=18,最佳 RMSprop (LR 1e-2) | 0.0768 |
| Nsize=18,Adadelta | 0.0888 |
| Nsize=18,最佳 Adagrad (LR 1e-1) | 0.1145 |
这些实验有助于验证模型的正确性,并揭示了一些未来工作的有趣方向。但是,迁移到更大的 ImageNet 数据集会带来自己的一系列有趣的挑战。
更大规模的训练:ImageNet
我们在 ImageNet 分类数据集上训练了 18 层、34 层、50 层和 101 层 ResNet 模型的变体。值得注意的是,我们通过使用不同的数据增强方法,实现了比公布结果更好的错误率。
我们还在训练一个 152 层 ResNet 模型,但截至撰写本文时,该模型尚未完成收敛。
我们使用了“更深入的卷积”中描述的尺度和纵横比增强,而不是 ResNet 论文中描述的尺度增强。使用 ResNet-34,这将 top-1 验证误差提高了大约 1.2 个百分点。我们还使用了“基于深度卷积神经网络的图像分类的一些改进”中描述的颜色增强,但发现它对 ResNet-34 的影响非常小。
模型更改
我们尝试将批量归一化层从构建块中最后一个卷积之后移动到加法之后。我们还尝试将瓶颈架构 (ResNet-50 和 ResNet-101) 中的步长为二的下采样从第一个 1x1 卷积移动到 3x3 卷积。
| 模型 | 批量归一化 | 步长为二的层 | top-1 单一裁剪误差 (%) |
|---|---|---|---|
| ResNet-18 | 卷积之后 | 3x3 | 30.6 |
| ResNet-18 | 加法之后 | 3x3 | 30.4 |
| ResNet-34 | 卷积之后 | 3x3 | 26.9 |
| ResNet-34 | 加法之后 | 3x3 | 27.0 |
| ResNet-50 | 卷积之后 | 3x3 | 24.5 |
| ResNet-50 | 加法之后 | 1x1 | 24.5 |
| ResNet-50 | 加法之后 | 3x3 | 24.2 |
批量归一化
Torch 使用指数移动平均值来计算用于批量归一化层推断的均值和方差估计。默认情况下,Torch 使用 0.1 的平滑因子来进行移动平均。我们发现,将平滑因子降至 0.003 并重新计算均值和方差可以将 top-1 误差率提高大约 0.2 个百分点。
多 GPU 训练
使用 4 个 NVIDIA Kepler GPU 和下面描述的优化,训练时间从 18 层模型的 3.5 天到 101 层模型的 14 天不等。
为了加快训练速度,我们使用了
在 4 个 GPU 上进行数据并行:这是加速深度学习模型训练的标准方法。输入是 N 个样本的小批量,这些样本被分成 N/4 个子批量,分别发送到每个 GPU 进行训练,网络参数在训练过程中在 GPU 之间进行通信。在 torch 中,可以使用 nn.DataParallelTable 完成此操作。
通过 CuDNN-4 进行基于 FFT 的卷积:使用 CuDNN Torch 绑定,可以通过将 cudnn.fastest 和 cudnn.benchmark 设置为 true 来选择最快的卷积内核。这会自动在您的 GPU 上对每个可能的算法进行基准测试,并选择最快的算法。这将单个 GPU 上每个小批量的执行时间缩短了大约40%,但由于额外的内核启动开销,多 GPU 情况下的速度会变慢。
多线程内核启动:基于 FFT 的卷积需要多个较小的内核,这些内核会快速连续地启动。虽然 CUDA 内核启动是异步的,但它们仍然需要一些 CPU 时间来排队。使用 DataParallelTable,第一个 GPU 的所有内核都会在任何内核排队到第二个、第三个和第四个 GPU 之前排队。为了解决这个问题,我们在 DataParallelTable 中引入了多线程模式,该模式使用每个 GPU 的一个线程来并行启动内核。
NCCL 集合:我们还使用了 NVIDIA NCCL 多 GPU 通信基元,这将训练速度提高了另外 4%。4% 听起来可能微不足道,但例如,在训练 Resnet-101 时,这相当于节省了 13 个小时。
GPU 内存优化
我们使用了一些技巧来将更大的 ResNet-101 和 ResNet-152 模型放入 4 个 GPU 上,每个 GPU 有 12 GB 的内存,同时仍然使用 256 的批量大小(ResNet-152 的批量大小为 128)。在反向传播过程中,一旦模块的 gradWeight 计算完成,gradInput 缓冲区就可以重复使用。在 Torch 中,实现这一点的一种简单方法是修改相同类型的模块以共享其底层存储。我们还使用了 ReLU 和 CAddTable 模块的原地变体。
添加这些内存优化只相当于 额外 10 行代码.
ResNets 与 GoogleNet 和 VGG-A/D 的速度比较
在图像分类的背景下,将ResNets的训练/推断时间与其他最先进的卷积神经网络模型进行比较很有趣。我们在 NVIDIA Titan X 上测量了 ResNet、VGG A、VGG D、批归一化 Inception 和 Inception v3 对 32 张图像的小批量进行完整前向和反向传播的时间。还列出了在 Imagenet-2012 数据集上的单裁剪验证的 top-1 错误率。
| 模型 | top-1 错误率 (%) | 时间 (ms) |
|---|---|---|
| VGG-A | 29.6 | 372 |
| VGG-D | 26.8 | 687 |
| ResNet-34 | 26.7 | 231 |
| BN-Inception | 25.2 | 192 |
| ResNet-50 | 24.0 | 403 |
| ResNet-101 | 22.4 | 649 |
| Inception-v3 | 21.2 | 494 |
虽然 ResNets 在效率方面绝对优于牛津大学的 VGG 模型,但 GoogleNet 在准确率/毫秒率方面似乎仍然更有效。
代码发布
我们正在发布训练 ResNets 的代码,以便其他人可以在自己的数据集上训练它们。在 ImageNet 上训练 ResNets 的代码位于 https://github.com/facebook/fb.resnet.torch。这也包括在 CIFAR-10 上训练的选项,**我们还描述了如何在自己的数据集上训练 ResNets**。
CIFAR-10 消融研究的代码位于 https://github.com/gcr/torch-residual-networks。
预训练模型
我们正在发布 ResNet-18、34、50 和 101 模型供社区中的每个人使用。我们希望这将有助于加速社区的研究。当 152 层模型完成训练后,我们将发布它。
预训练模型可在 此链接 获取,并 包括在您自己的数据集上进行微调的说明。
我们的模型比 原始 ResNet 模型 具有更高的准确率,这很可能是由于纵横比增强造成的。下表显示了原始残差网络论文和我们发布的模型之间的单裁剪 top-1 验证错误率的比较。
如您所见,我们的 ResNet-101 模型的准确率高于 MSR-A 的 ResNet-152 模型。我们没有在验证错误率上对我们的模型进行大量调整,因此没有过度拟合验证集。事实上,我们只训练了 ResNet-101 模型的一个实例,没有任何超参数扫描。
| 模型 | 原始 top-1 错误率 (%) | 我们的 top-1 错误率 (%) |
|---|---|---|
| ResNet-50 | 24.7 | 24.0 |
| ResNet-101 | 23.6 | 22.4 |
| ResNet-152 | 23.0 | N/A |
结论
我们介绍了我们对模型选择、优化以及我们的工程优化的研究,在训练深度残差网络的背景下。我们发布了优化的训练代码以及预训练模型,希望这能造福社区。
#####################################################################################################################
致谢
感谢何凯明讨论原始论文中的模糊和缺失细节,并帮助我们重现结果。
感谢 Ross Girshick、Piotr Dollar、Tsung-yi Lin 和 Adam Lerer 的讨论。
感谢 Natalia Gimelshein、Nicolas Vasilache、Jeff Johnson 在多 GPU 优化方面的代码和讨论。
参考文献
[1] He, Kaiming 等。“用于图像识别的深度残差学习。”arXiv 预印本 arXiv:1512.03385 (2015)。
[2] Ioffe, Sergey 和 Christian Szegedy。“批量归一化:通过减少内部协变量移位来加速深度网络训练。”arXiv 预印本 arXiv:1502.03167 (2015)。
[3] Simonyan, Karen 和 Andrew Zisserman。“用于大规模图像识别的非常深的卷积神经网络。”arXiv 预印本 arXiv:1409.1556 (2014)。
由 Disqus 提供支持的评论