使用 Torch 生成人脸
在这篇博文中,我们将实现一个生成图像模型,该模型可以将随机噪声转换为人脸图像!代码可在 Github 上获取.

对于这项任务,我们使用了一个生成对抗网络 (GAN) [1]。GAN 由两个组件组成:一个生成器,它将随机噪声转换为图像,以及一个鉴别器,它试图区分生成的图像和真实图像。这里,“真实”意味着该图像是来自我们的训练集的图像,而不是生成的伪造图像。
为了训练模型,我们让鉴别器和生成器互相博弈。我们首先向鉴别器展示一个混合批次,其中包含来自我们训练集的真实图像和生成器生成的伪造图像。然后,我们同时优化鉴别器,使其对伪造图像回答“否”,对真实图像回答“是”,并优化生成器,使其欺骗鉴别器相信伪造图像是真实的。这对应于最小化关于鉴别器的分类误差并最大化关于生成器的分类误差。通过仔细优化,生成器和鉴别器都会改进,最终生成器将开始生成令人信服的图像。
实现 GAN
我们将生成器和鉴别器实现为卷积网络,并使用随机梯度下降法对其进行训练。
鉴别器是一个标准的卷积网络,具有连续的卷积、ReLU 激活、最大池化和丢弃块。
model_D = nn.Sequential()
model_D:add(cudnn.SpatialConvolution(3, 32, 5, 5, 1, 1, 2, 2))
model_D:add(cudnn.SpatialMaxPooling(2,2))
model_D:add(cudnn.ReLU(true))
model_D:add(nn.SpatialDropout(0.2))
model_D:add(cudnn.SpatialConvolution(32, 64, 5, 5, 1, 1, 2, 2))
model_D:add(cudnn.SpatialMaxPooling(2,2))
model_D:add(cudnn.ReLU(true))
model_D:add(nn.SpatialDropout(0.2))
model_D:add(cudnn.SpatialConvolution(64, 96, 5, 5, 1, 1, 2, 2))
model_D:add(cudnn.ReLU(true))
model_D:add(cudnn.SpatialMaxPooling(2,2))
model_D:add(nn.SpatialDropout(0.2))
model_D:add(nn.Reshape(8*8*96))
model_D:add(nn.Linear(8*8*96, 1024))
model_D:add(cudnn.ReLU(true))
model_D:add(nn.Dropout())
model_D:add(nn.Linear(1024,1))
model_D:add(nn.Sigmoid())
这是一个非常标准的架构。鉴别器以 64x64 RGB 图像作为输入,并使用单个 sigmoid 输出预测“是”或“否”。
生成器则朝着相反的方向进行。我们从一个小的图像开始,它被重复地进行上采样和卷积
x_input = nn.Identity()()
lg = nn.Linear(opt.noiseDim, 128*8*8)(x_input)
lg = nn.Reshape(128, 8, 8)(lg)
lg = cudnn.ReLU(true)(lg)
lg = nn.SpatialUpSamplingNearest(2)(lg)
lg = cudnn.SpatialConvolution(128, 256, 5, 5, 1, 1, 2, 2)(lg)
lg = nn.SpatialBatchNormalization(256)(lg)
lg = cudnn.ReLU(true)(lg)
lg = nn.SpatialUpSamplingNearest(2)(lg)
lg = cudnn.SpatialConvolution(256, 256, 5, 5, 1, 1, 2, 2)(lg)
lg = nn.SpatialBatchNormalization(256)(lg)
lg = cudnn.ReLU(true)(lg)
lg = nn.SpatialUpSamplingNearest(2)(lg)
lg = cudnn.SpatialConvolution(256, 128, 5, 5, 1, 1, 2, 2)(lg)
lg = nn.SpatialBatchNormalization(128)(lg)
lg = cudnn.ReLU(true)(lg)
lg = cudnn.SpatialConvolution(128, 3, 3, 3, 1, 1, 1, 1)(lg)
model_G = nn.gModule({x_input}, {lg})
要生成图像,我们将以服从 N(0,1) 分布的噪声作为生成器的输入。经过成功训练后,输出应该是具有意义的图像!
local noise_inputs = torch.Tensor(N, opt.noiseDim)
noise_inputs:normal(0, 1)
local samples = model_G:forward(noise_inputs)
平衡 GAN 游戏
原则上,GAN 优化游戏很简单。我们使用二元交叉熵来优化鉴别器中的参数。之后,我们使用二元交叉熵来优化生成器,使其欺骗鉴别器。也就是说,您经常会发现自己得到的生成器输出并不令人信服

这种乱七八糟的东西,是未经适当训练的生成器典型的表现!
为了促进训练,需要一些技巧:首先,我们需要确保生成器和鉴别器都没有变得比另一个过于强大。如果鉴别器“获胜”并正确地对所有图像进行分类,则误差信号将很差,生成器将无法从中学习。相反,如果我们允许生成器获胜,它通常会利用鉴别器中不重要的弱点(例如,通过将整个图像涂成蓝色),这不是我们想要的。
我们通过绘制三个量来监控训练
- 生成器在欺骗鉴别器方面的能力(gen)
- 鉴别器在将伪造图像分类为伪造图像方面的能力(fake)
- 鉴别器在将真实图像分类为真实图像方面的能力(real)
下面,我们在三个独立网络的训练过程中绘制了这些量。在面板 A)中,我们通过添加批次归一化层使鉴别器过于强大。训练永远不会收敛,因为 sigmoid 饱和,导致反向传播的误差信号很差。
为了缓解这个问题,我们监控鉴别器对真实和伪造图像进行分类的能力,以及生成器欺骗鉴别器的能力。如果其中一个网络过于强大,我们会根据以下规则跳过更新其参数。收敛情况如面板 B)所示。我们还从鉴别器中去掉了批次归一化。
local margin = 0.3
sgdState_D.optimize = true
sgdState_G.optimize = true
if err_F < margin or err_R < margin then
sgdState_D.optimize = false
end
if err_F > (1.0-margin) or err_R > (1.0-margin) then
sgdState_G.optimize = false
end
if sgdState_G.optimize == false and sgdState_D.optimize == false then
sgdState_G.optimize = true
sgdState_D.optimize = true
end
在每一批次中不更新参数似乎有点浪费。因此,我们尝试另一种启发式方法,即在生成器表现不佳的情况下对鉴别器进行正则化。如果生成器没有达到目标范围,我们就会增加鉴别器的 L2 惩罚。如果生成器在 50% 的情况下欺骗了鉴别器,则误差将约为 log(0.5) ~=0.69。我们将目标范围设置为 0.9-1.2,即鉴别器应该比生成器更强大,但不能过于强大。训练如面板 C)所示(请注意,x 轴是不同的)
if f > 1.3 then -- f is generator error
sgdState_D.coefL2 = sgdState_D.coefL2 + 0.00001
end
if f < 0.9 then
sgdState_D.coefL2 = sgdState_D.coefL2 - 0.00001
end
if sgdState_D.coefL2 < 0 then
sgdState_D.coefL2 = 0
end
<img src="https://raw.githubusercontent.com/torch/torch.github.io/master/blog/_posts/images/monitor.png", width="90%">
这些简单的启发式方法似乎有效,但肯定还有改进的空间。最重要的是,它们允许我们提高学习速率并使用 RMSProp。
成功训练 GAN 还需要一些其他技巧
-
批次归一化在生成器中使用时可以大大加快训练速度。在鉴别器中使用批次归一化很危险,因为鉴别器会变得过于强大。
-
鉴别器需要大量的丢弃,以避免由生成器利用鉴别器弱点而引起的振荡行为。丢弃也可以在生成器中使用。
-
限制鉴别器的容量可能是有益的。这可以通过减少其特征数量来实现,使得生成器包含更多参数。
我们制作了一个视频,展示了模型在训练的前三个 epoch中生成的图像。根据我们的经验,如果模型最初生成的图像非常多彩且毫无意义,你不必太担心,但如果所有生成的图像都相同或几乎相同,则模型可能存在问题。
生成人脸
我们使用来自Labeled Faces in the Wild 数据集的对齐裁剪图像训练我们的 GAN。在经过大约 5 个 epoch 后(在 GPU 上大约需要 30 分钟),您应该开始看到一些恐怖的面孔(左侧)。经过 100 个 epoch 后,面孔会显得更赏心悦目(右侧)。

经过一天的训练,我们得到了在 GAN 的潜在空间中相当不错的行走轨迹(YouTube 上的完整视频)

更进一步
虽然从噪声生成图像很有趣,但 GAN 无法让我们控制潜在空间。
一个相关的生成模型是变分自动编码器 (VAE) [3],其中解码器将来自先验分布的样本映射到数据集样本 - 与 GAN 生成器非常相似。
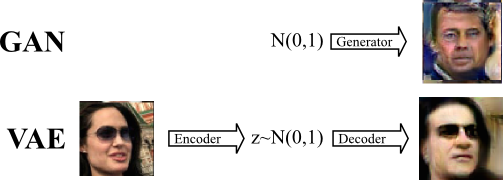
VAE 解码器的训练方式不同,因为我们试图最小化解码图像与编码图像的像素重建误差。对于图像来说,这个误差项是有问题的,因为平移的惩罚比人类视觉感知到的微小误差要大得多。在实践中,这意味着 VAE 倾向于生成具有正确全局主题的平滑图像,而 GAN 生成的图像具有更正确的局部风格,而对全局结构的重视程度较低。
以下是一些 VAE 从随机样本 z ~ N(0,1) 生成的图像

虽然图像中明显包含人脸,但由于图像过于平滑,所以显得有些无聊。为了改进这一点,我们尝试将 VAE 和 GAN 结合到一个模型中
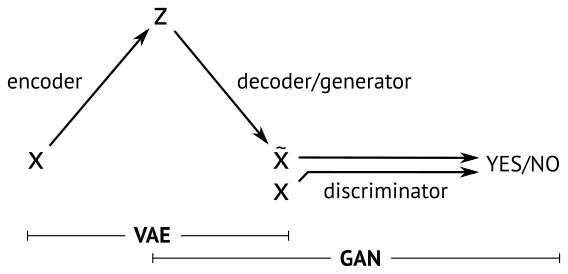
我们让 GAN 和 VAE 共享潜在空间 z ~ N(0,1) 以及解码器/生成器网络。我们在训练模型时将误差项结合起来
误差 = [VAE 先验] + [VAE 重建误差] + [GAN 误差]
为了优化组合模型的参数,我们最小化 VAE 项,同时平衡 GAN 项,如前所述。解码器/生成器参数的梯度会加权,以确保两个模型都有合理的贡献。
下面展示了由 VAE/GAN 模型生成的图像。

与普通的 VAE 相比,VAE/GAN 图像更有趣,因为它们包含更多细节。最显著的是,VAE/GAN 学习了如何重建一副眼镜。
结论
让 GAN 成功训练起来非常困难。在这篇博文中,我们分享了一些在训练 GAN 时应该做和不应该做的事情。最后,我们展示了 GAN 和 VAE 可以组合成一个有趣的模型。未来的工作将表明这种组合是否可以改进例如半监督学习。
致谢
感谢 Eyescream 的作者 [2] 公开他们的代码。我们的代码很大程度上基于为 LAPGAN 论文 [2] 发布的 CIFAR 代码。
Y0st 的 Torch VAE:https://github.com/y0ast/VAE-Torch
参考文献
[1] Goodfellow, Ian 等。“生成对抗网络。”神经信息处理系统进展。2014 年。
[2] Denton, Emily 等。“使用拉普拉斯金字塔对抗网络的深度生成图像模型。”arXiv 预印本 arXiv:1506.05751 (2015).
[3] Kingma, Diederik P. 和 Max Welling。“自动编码变分贝叶斯。”arXiv 预印本 arXiv:1312.6114 (2013).
由 Disqus 提供支持的评论