空间变换网络的力量
tl;dr
几周前,Google DeepMind 发布了一篇很棒的论文,名为 空间变换网络,旨在以一种非常优雅的方式提升 CNN 的几何不变性。
这种方法对我们在 Moodstocks 的吸引力非常大,因此我们决定实施它,看看它在 GTSRB 这样不太简单的数据库上的表现。
最终,空间变换网络使我们能够以更简单的流程(没有抖动,没有并行网络,没有花哨的归一化技术...)超越最先进水平。
GTSRB 数据库
GTSRB 数据库(德国交通标志识别基准)由神经信息学研究所的 这里 提供。它是在 2011 年为一场比赛发布的 (结果)。图像分布在 43 种不同的交通标志类型中,总共包含 39,209 个训练样本和 12,630 个测试样本。

我们非常喜欢 Moodstocks 中的这个数据库:它很轻量级,但又足够难以测试新想法。据记录,比赛的获胜者使用**25 个网络组成的委员会**,并使用了一系列增强和数据归一化技术,实现了 99.46% 的 top-1 准确率。
空间变换网络
空间变换器 [1] 的目标是在您的基础网络中添加一个能够对输入执行显式几何变换的层。变换的参数通过标准反向传播算法学习,这意味着不需要额外的數據或监督。
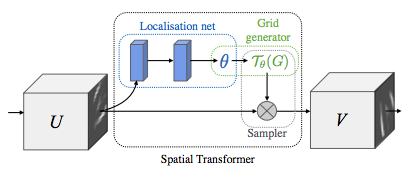
该层由 3 个元素组成
- 定位网络将原始图像作为输入,并输出我们想要应用的变换参数。
- 网格生成器在输入图像中生成一个坐标网格,对应于输出图像中的每个像素。
- 采样器使用网格生成器给出的网格生成输出图像。
例如,以下是您在训练网络后(其第一层是 ST)得到的

左侧是输入图像。中间是您看到输入图像的哪一部分被采样了。右侧是空间变换器输出图像。
结果
IDSIA 小组在 2011 年的比赛中以 99.46% 的 top-1 准确率获胜。我们使用更简单的流程实现了99.61% 的 top-1 准确率
- (i) 通过花哨的归一化技术获得原始数据库的 5 个版本
- (ii) 缩放平移和旋转
- (iii) 25 个网络,每个网络具有 3 个卷积层和 2 个全连接层
- (iv) 一个网络,具有 3 个卷积层和 2 个全连接层 + 2 个空间变换层
解释
鉴于这些良好的结果,我们想对空间变换器正在学习哪种类型的变换有一些见解。由于我们在网络的开头有一个空间变换器,我们可以通过查看变换后的输入图像来轻松地可视化其影响。
在训练时
这里的目标是可视化空间变换器在训练过程中的行为。
在下面的动画中,您可以看到
- 左侧是作为输入使用的原始图像,
- 右侧是空间变换器生成的变换后的图像,
- 底部是一个计数器,代表训练步骤(0 = 训练前,10/10 = 第 1 个时期结束)。

注意:输入图像上的白点显示被采样图像部分的角点。下面也适用。
正如预期的那样,我们看到在训练过程中,空间变换器学会了专注于交通标志,逐渐学习去除背景。
训练后
这里的目标是可视化空间变换器(一旦训练完成)在输入包含几何噪声的情况下生成稳定输出的能力。
据记录,GTSRB 数据库最初是通过从接近交通标志时拍摄的视频序列中提取图像生成的。
下面的动画显示了每个此类序列的图像(左侧)以及空间变换器的相应输出(右侧)。

我们可以看到,即使输入图像存在很大的可变性(比例和图像中的位置),空间变换器的输出仍然几乎保持静止。
这证实了我们对空间变换器如何简化网络其余部分任务的直觉:学习只转发输入的有趣部分并去除几何噪声。
空间变换器以端到端的方式学习了这些变换,而无需对反向传播算法进行任何修改,也无需任何额外的注释。
代码
我们利用了 Maxime Oquab 在其很棒的 stnbhwd 项目中编写的网格生成器和采样器。我们在定位网络和网格生成器之间添加了一个模块,让我们可以限制可能的变换。
使用这些模块,使用 torch 逻辑创建空间变换层就像
完整的代码可在 Moodstocks Github 上获取。我们设计它是为了让您在数据库上执行各种测试。如果您想重现我们的结果,您只需运行以下命令
# This takes ~5 min per epoch and 1750MB ram on a Titan X
luajit main.lua -n -1 --st --locnet 200,300,200 --locnet3 150,150,150 --net idsia_net.lua --cnn 150,200,300,350 -e 14
它基本上将在基线 IDSIA 网络 (idsia_net.lua --cnn 150,200,300,350) 中添加两个空间变换层 (--st --locnet 200,300,200 --locnet3 150,150,150) 并运行 14 个时期 (-e 14)。当然,您还可以使用我们的代码做更多的事情,所以请随时查看我们存储库中的 文档!
结论
空间变换网络是一种非常吸引人的方法,可以提升 CNN 的几何不变性,从而提高您的 top-1 准确率。它们学习考虑与您的数据集相关的几何变换,而无需额外的监督。使用它们,我们设法在不太简单的数据库 (GTSRB) 上超越了最先进水平,同时极大地简化了流程。请随时使用 我们的代码 重现我们的结果,甚至获得更好的结果:我们提供了一种花哨的方法来 批量基准测试 配置以帮助您做到这一点。祝您玩得开心!
- Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, 空间变换网络 [arxiv]
- P. Sermanet, Y. LeCun, 使用多尺度卷积网络进行交通标志识别 [link]
- D. Ciresan, U. Meier, J. Masci, J. Schmidhuber, 用于交通标志分类的多列深度神经网络 [link]